「robots.txt によりブロックされました」が発生する原因と対処法
「robots.txt によりブロックされました」は、Search Consoleのインデックスカバレッジレポートに表示されるステータスの一つで、robots.txtによってGooglebotのクロールがブロックされている状態です。
ただし、このステータスが表示されたからといって、すべてのケースで対処が必要なわけではありません。
意図的にブロックしているページなら放置で問題なく、本来インデックスさせたいページがブロックされている場合のみ修正が必要です。
Google公式ドキュメントをもとに、事業会社のSEO担当者が迷わず対応できるよう解説していきます。
インデックス状態の把握が大変という方は、SEOサイト管理自動化ツール「inSite(インサイト)」を試してみてください。
inSiteのインデックスチェック機能では、サイト内のページのクロール状態を毎日自動でチェックします。
どれだけのページがインデックスされてなくて原因は何なのか、クローラーは定期的に来ているのかといった情報を常に監視することができます。
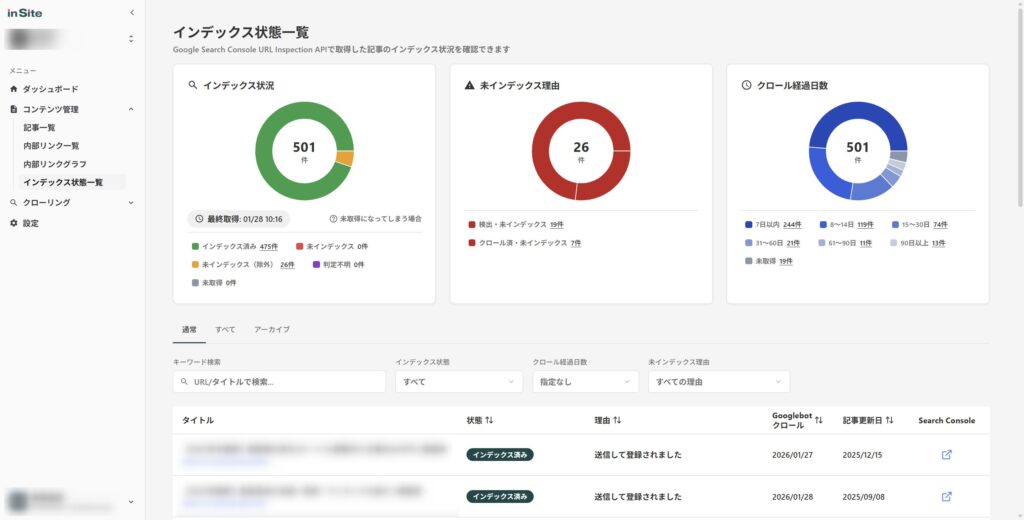
1ページずつURL検査をしなければわからないインデックス状態。
inSiteを使えばこれを常に把握できるため、効率よくSEOにおける有効な打ち手を考えることができます。
ページのインデックス率向上や、ページの評価をアップさせるリライトの効率化にかなり使えると思うので、ぜひお試しください。
「robots.txt によりブロックされました」とは?
「robots.txt によりブロックされました」は、Search Consoleの「ページのインデックス登録」レポートで確認できるステータスの一つで、robots.txtでDisallowルールが設定されているURLに対して、Googleのクロールがブロックされている状態です。
意図的にクロールを制御している場合は問題ありませんが、このステータスが付いたページは検索結果での扱いにも関わるため、仕組みを理解しておくことが大切です。
Google Search Consoleヘルプでは、以下のように説明されています。
robots.txt のルールによってページが Google に対してブロックされている場合、そのページは Google 検索の検索結果に表示されない可能性が高く、表示されたとしても結果には説明文が含まれません。
Google Search Console ヘルプ「robots.txt によってブロックされているページのブロックを解除する」
なお、Search Consoleには似ているステータスとして「robots.txtによりブロックされましたが、インデックスに登録しました」という表示もあります。
一見矛盾しているように見えますが、Google Search Centralでは以下のように説明されています。
Google では、robots.txt ファイルでブロックされているコンテンツをクロールしたりインデックスに登録したりすることはありませんが、ブロック対象の URL がウェブ上の他の場所からリンクされている場合、その URL を検出してインデックスに登録する可能性はあります。
そのため、該当の URL アドレスや、場合によってはその他の公開情報(該当ページへのリンクのアンカー テキストなど)が、Google 検索結果に表示されることもあります。
Google Search Central「robots.txt の概要とガイド」
この状態が発生すると、検索結果にページは表示されるものの、Googleがページの内容を読み取れていないため、タイトルやディスクリプションが正しく表示されない可能性があります。
≫inSiteでサイトのインデックス状況をチェックしてみる(無料)
「robots.txt によりブロックされました」が表示される原因
「robots.txt によりブロックされました」が表示される原因は、robots.txtのDisallowルールに該当するURLが存在していることです。
ただし、Disallowが設定される背景はさまざまです。ここでは代表的な3つのパターンを紹介します。
①意図的にクロールをブロックしている
管理画面や会員専用ページなど、検索結果に表示させる必要のないページに対して、サイト管理者が意図的にDisallowルールを設定しているケースです。
この場合は正常な動作なので、対処は不要です。
②サイト移行時に開発環境の設定が残っている
サイトリニューアルやドメイン移行の際に、開発環境のrobots.txt設定がそのまま本番環境に引き継がれてしまうケースです。
開発環境ではサイト全体をブロックするDisallow: /を設定することが一般的なため、これが残っていると本来公開すべきページもブロックされてしまいます。
③CMSのデフォルト設定が有効になっている
WordPressの場合、「設定」→「表示設定」→「検索エンジンがサイトをインデックスしないようにする」にチェックが入っていると、robots.txtでサイト全体がブロックされるほか、各ページにnoindexメタタグも追加されます。
テスト環境から本番公開に切り替える際に、この設定を戻し忘れるケースが少なくありません。
≫inSiteでサイトのインデックス状況をチェックしてみる(無料)
対処が必要かどうかの判断基準
このステータスが表示されているすべてのページで対処が必要なわけではありません。
まずは対処すべきかどうかを判断しましょう。
| 状況 | 対処 | 具体例 |
|---|---|---|
| インデックスさせたいページがブロックされている | 必要 | 商品ページ、ブログ記事、サービスページ |
| 意図的にブロックしているページ | 不要 | 管理画面、会員専用ページ、テストページ |
| インデックス不要なページ | 不要 | サンクスページ、内部検索結果ページ |
▼確認手順
- Search Consoleの「インデックス」→「ページ」を開く
- 「ページがインデックスに登録されなかった理由」から「robots.txtによりブロックされました」を選択
- 該当URLの一覧を確認
- 各URLについて、インデックスさせたいかどうかを判断
重要なページがブロックされている場合は対処が必要です。
一方、管理画面やテストページなど、そもそも検索結果に表示させたくないページがブロックされている場合は、正しく機能している状態なので放置で問題ありません。
≫inSiteでサイトのインデックス状況をチェックしてみる(無料)
インデックス登録させたい場合は”robots.txt”の記述を修正する
本来インデックスさせたいページがrobots.txtでブロックされている場合は、robots.txtの修正が必要です。
ブロック対象のDisallowルールを特定し、削除または修正すれば解決できます。
まず、現在のrobots.txtの内容を確認しましょう。
ブラウザで「https://あなたのドメイン/robots.txt」にアクセスすると、設定内容を表示できます。
▼修正前の例
User-agent: *
Disallow: /products/
Disallow: /admin/この設定では「/products/」と「/admin/」以下のすべてのURLがブロックされます。
管理画面(/admin/)はブロックしたままでよいですが、商品ページ(/products/)はインデックスさせたいとします。
▼修正後の例
User-agent: *
Disallow: /admin/不要なDisallow: /products/の行を削除するだけで、商品ページへのクロールが許可されます。
ブロックを維持したいページ(/admin/)はそのまま残しておきましょう。
robots.txtの編集は、FTP/SFTPでサーバーに直接アップロードするか、CMSの管理画面から行います。
WordPressの場合は、「設定」→「表示設定」で「検索エンジンがサイトをインデックスしないようにする」のチェックを外すことで、自動生成されるrobots.txtが変更されます。
robots.txtの詳しい記述方法については、Google Search Central「robots.txtの概要とガイド」を参照してください。
≫inSiteでサイトのインデックス状況をチェックしてみる(無料)
修正後の検証と再クロール申請手順
robots.txtを修正したら、URL検査ツールで該当URLがブロックされていないことを確認しましょう。
まずは、ブラウザで再度「https://あなたのドメイン/robots.txt」にアクセスし、該当するDisallowルールが削除されていることを確認してください。
確認できたら、Search Consoleで検証をリクエストしましょう。方法は2つあります。
方法1: 「修正を検証」ボタンを使う(複数URLの場合に便利)
Search Consoleの「インデックス」→「ページ」から「robots.txtによりブロックされました」のステータスを開き、「修正を検証」ボタンをクリックします。
これにより、該当するURLをGoogleがまとめて再クロールし、問題が解消されたか検証してくれます。
方法2: URL検査ツールを使う(個別URLの場合)
Search ConsoleのURL検査ツールで該当URLを検査し、「インデックス登録をリクエスト」をクリックしてください。
特定のページだけ急ぎで対応したい場合はこちらがおすすめです。
なお、反映までには数日から数週間かかることがあります。
大量のURLが該当する場合は、URL Inspection APIを使ってインデックス状態を一括確認するツールを作っておくと効率的に進捗を確認できます。
≫inSiteでサイトのインデックス状況をチェックしてみる(無料)
robots.txtとnoindexの違いと使い分け
robots.txtでクロールをブロックしていても、外部サイトからリンクされている場合などに、Googleがそのページをインデックスに登録してしまうことがあります。
この場合、Search Consoleには「robots.txtによりブロックされましたが、インデックスに登録しました」というステータスが表示され、内容が正しく表示されないまま検索結果に載ってしまう可能性があります。
このように、robots.txtとnoindexは役割が異なります。混同しやすいため、違いを整理して活用するようにしましょう。
| 項目 | robots.txt(Disallow) | noindex |
|---|---|---|
| 役割 | クロールの制御 | インデックスの制御 |
| 効果 | Googlebotがアクセスしない | 検索結果に表示されない |
| クロール | ブロック | 許可(読み取る必要あり) |
| インデックス | 直接制御できない ※外部リンク等でインデックスされる可能性あり | 制御できる |
| 適した用途 | クロールバジェットの節約 | 検索結果からの除外 |
以下の判断基準で使い分けるようにしてください。
- クロールバジェットを節約したい場合は「robots.txt」
- サイト規模が大きく、重要なページに優先的にクロールさせたい場合に有効です。
- 検索結果に表示させたくない場合は「noindex」
- 確実にインデックス登録を防ぎたい場合はnoindexを使います。
≫inSiteでサイトのインデックス状況をチェックしてみる(無料)
まとめ
「robots.txt によりブロックされました」は、robots.txtによってGooglebotのクロールがブロックされているページに対して表示されるSearch Consoleのステータスです。
対処のポイントをまとめると以下のとおりです。
- 意図的なブロックなら対処不要
- 管理画面やテストページなど、検索に出したくないページは放置でOK
- 重要なページがブロックされていたら修正
- robots.txtのDisallowルールを削除または修正
- インデックスを防ぎたいならnoindexを使う
- robots.txtはインデックス登録を防ぐ仕組みではない
定期的にSearch Consoleを確認し、意図しないページがブロックされていないかチェックすることをおすすめします。
サイト全体のインデックス状況やSEO課題を効率的に管理したい方は、inSiteの無料会員登録をご検討ください。
インデックス状態の把握が大変という方は、SEOサイト管理自動化ツール「inSite(インサイト)」を試してみてください。
inSiteのインデックスチェック機能では、サイト内のページのクロール状態を毎日自動でチェックします。
どれだけのページがインデックスされてなくて原因は何なのか、クローラーは定期的に来ているのかといった情報を常に監視することができます。
1ページずつURL検査をしなければわからないインデックス状態。
inSiteを使えばこれを常に把握できるため、効率よくSEOにおける有効な打ち手を考えることができます。
ページのインデックス率向上や、ページの評価をアップさせるリライトの効率化にかなり使えると思うので、ぜひお試しください。

