Google Search Consoleの「ページのインデックス登録」レポートで表示される「robots.txtによりブロックされましたが、インデックスに登録しました」とは、robots.txtでクロールをブロックしているURLが、何らかの経路でGoogleに認識されインデックスに登録された状態のことです。
このステータスは警告であり、エラーではありません。そのため、すべてのケースで対処が必要なわけではありません。
対処の要否は「そのページをインデックスさせたいか」で判断します。判断基準から対処手順まで解説します。
\ インデックス管理を自動化 /
inSite(インサイト)
サイト内のページのクロール状態を毎日自動でチェック。どれだけのページがインデックスされてなくて原因は何なのか、クローラーは定期的に来ているのかといった情報を常に監視できます。
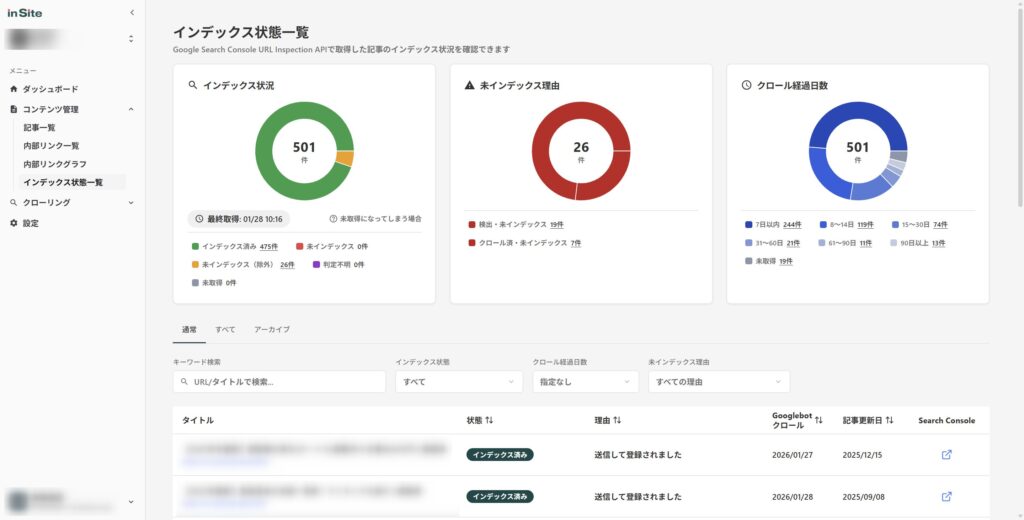
1ページずつURL検査をしなければわからないインデックス状態を常に把握でき、効率よくSEOの打ち手を考えることができます。
無料で試してみる ↗「robots.txtによりブロックされましたが、インデックスに登録しました」とは?
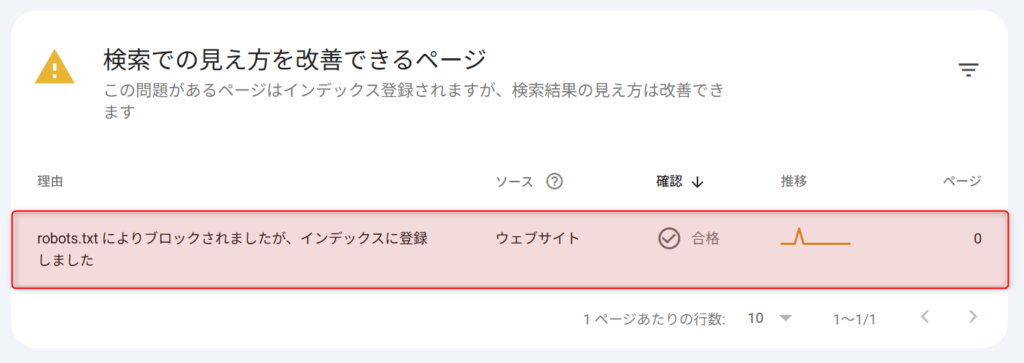
Google Search Consoleの「ページのインデックス登録」レポートで表示される「robots.txtによりブロックされましたが、インデックスに登録しました」とは、robots.txtでクロールをブロックしているURLが、何らかの経路でGoogleに認識されインデックスに登録された状態のことです。
このステータスは「有効(警告あり)」カテゴリに分類されます。サイトに致命的な問題が起きているわけではありませんが、状況によっては対処が必要です。
Googleの公式ヘルプでは、次のように説明されています。
“If your web page is blocked with a robots.txt file, its URL can still appear in search results, but the search result won’t have a description.”
(和訳)
robots.txtファイルでブロックされたウェブページでも、URLは検索結果に表示されることがある。ただし、検索結果に説明文は表示されない
実際の検索結果では「このページの情報はありません」と表示されます。Googleがページの内容を読み取れないため、タイトルやディスクリプションを生成できないのです。
なお、似たステータスに「robots.txtによりブロックされました」がありますが、こちらは単にブロックされた状態を指すものです。本記事で扱う「ブロックされたのにインデックスに登録された」とは状況が異なります。
「robots.txtによりブロックされました」への対処は、「robots.txt によりブロックされました」の対処法をご覧ください。
robots.txtでブロックしているのにインデックスされる仕組み
robots.txtでブロックしているのにインデックスされるのは、robots.txtはクロール(ページの中身を読みに行くこと)を制御するだけであり、インデックス登録を直接防ぐ仕組みではないためです。
インデックスさせないためには、Googleに「noindexタグ」を認識してもらう必要がありますが、robots.txtでブロックしているとGoogleはページの中身を読めないため、noindexタグも把握できません。
一方で、外部リンク・サイトマップ・その他の経路でGoogleにURLが認識されると、ページの中身をクロールできなくても、そのURLがインデックスに登録されることがあります。
以下のYouTube動画も参考にしてください。
robots.txtはクロール制御であり、インデックス制御ではない
robots.txtの役割は「クローラーのアクセスを制御すること」です。インデックスを制御して検索結果からページを除外する仕組みではありません。
Googleの公式ドキュメントでも、この点は明確に述べられています。
“A robots.txt file tells search engine crawlers which URLs the crawler can access on your site. This is used mainly to avoid overloading your site with requests; it is not a mechanism for keeping a web page out of Google.”
(和訳)
robots.txtファイルは、クローラーがアクセスできるURLを指定するもの。主にサーバーへの過剰なリクエストを防ぐ目的で使われ、ページをGoogleから除外する仕組みではない
GoogleのGary Illyesも「robots.txtはクロール用、メタタグはインデックス用」と明言しています。
Technically, robots.txt is for crawling. The meta tags are for indexing. During indexing they’d be applied at the same stage so there’s no good reason to have both of them
— Gary 鯨理/경리 Illyes (so official, trust me) (@methode) April 18, 2019
ちなみに、robots.txtは2022年にIETF RFC 9309として正式に規格化されました。この規格の共著者のひとりがGary Illyes本人です。
RFC 9309でもrobots.txtは「クローラーによるコンテンツアクセスの制御」と定義されており、インデックス制御の手段とは位置づけられていません。
リンク経由でURLだけがインデックスされる
robots.txtでブロックされたページでも、Googleは外部リンクや内部リンク、サイトマップなどからURLの存在を認識します。
GoogleのJohn Muellerも次のように述べています。
「Googlebotがページをクロールできなくても、リンクを通じてページを発見しインデックスできる」
Pages Indexed, Though Being Blocked by robots.txt: Insights from John Mueller
つまり、Googleはページの内容はクロールしないものの、URL自体とリンク元のアンカーテキストなどの外部情報をもとにインデックスに登録する可能性があるわけです。
robots.txtは「クロールの制御」であってインデックスの制御ではないため、外部リンクやサイトマップなどからURLの存在がGoogleに認識されると、クロールをブロックしていてもURL情報だけでインデックスに登録される場合があります。
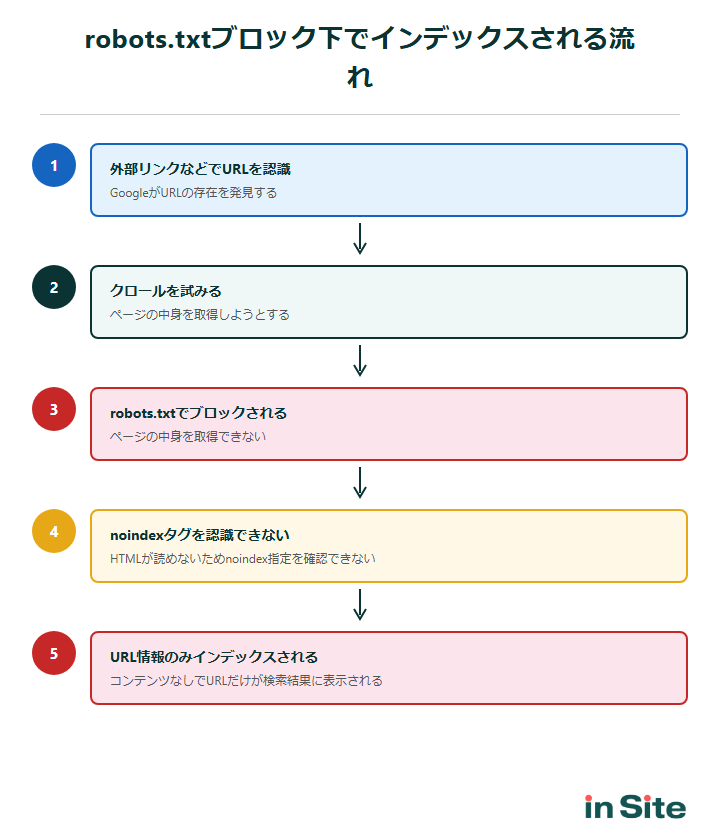
流れを整理すると以下のとおりです。
- 外部リンクや内部リンク、サイトマップなどからGoogleがURLの存在を認識する
- ページの内容を取得するためにクロールを試みる
- robots.txtによってブロックされ、ページの内容を取得できない
- noindexタグもページ内にあるため、ブロックされた状態では認識できない
- ページの中身がない状態のまま、URL情報だけでインデックスに登録される
これが、Search Consoleで「robots.txtによりブロックされましたが、インデックスに登録しました」と表示される原因です。
対処が必要なケースと不要なケースの判断基準
このステータスが表示されたとき、まず判断すべきは「そのページをインデックスさせたいかどうか」です。対処の要否は状況によって異なるため、ケースごとの見極めが大切になります。

対処が必要なケース
以下のようなケースでは、早めの対処をおすすめします。
- インデックスさせたいページがブロックされている(設定ミス)
robots.txtの記述ミスで、本来インデックスさせたいページをブロックしてしまっているケース。robots.txtのDisallowルールを修正する必要があります。 - インデックスさせたくないページが登録されている
管理画面やテストページなど、検索結果に表示したくないページがインデックスされているケース。robots.txtのブロックを解除したうえで、noindexを設定しましょう。 - 検索結果で「このページの情報はありません」と表示されている
ブランドに関わるページでこの表示が出ると、ユーザーに不信感を与えかねません。クリック率にも影響するため、早急な対処が望ましいでしょう。
実際に、Firebrand Marketing社の事例では、「robots.txtによりブロックされましたが、インデックスに登録しました」の修正後にインプレッションが470%増加し、クリック数も315%増加したという報告があります。
対処が不要なケース(放置OK)
一方、以下のケースでは対処しなくても問題ありません。
- 意図的にブロックしており、検索結果に表示されても支障がないページ
検索結果に表示されても実害がなければ放置で構いません。 - 該当URLへの検索流入がほとんどないケース
実質的にSEOへの影響がゼロであれば、対処の優先度は低いと判断してよいでしょう。 - 少数のURLのみが該当し、サイト全体への影響が小さいケース
数ページ程度であれば、サイト全体の評価に直接的な悪影響を与えることは考えにくいです。
Google公式ドキュメントでも、このステータスは「有効(警告あり)」であり、サイト全体のインデックスに深刻な問題があるわけではないとされています。
状況別の対処方法
対処の方法は「インデックスさせたい場合」と「除外したい場合」で異なります。
インデックスさせたい場合の手順
robots.txtの設定ミスなどでブロックしてしまっており、本当はインデックスさせたい場合は、以下の手順で対処してください。
まずは、robots.txtのDisallowから該当ページのURLを削除しましょう。
# 修正前
User-agent: *
Disallow: /example-page/
# 修正後(該当行を削除)
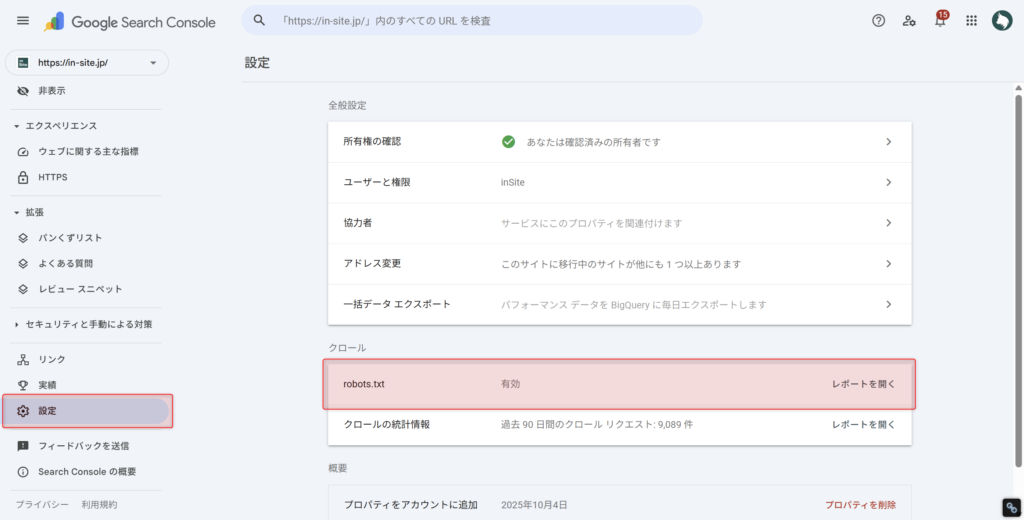
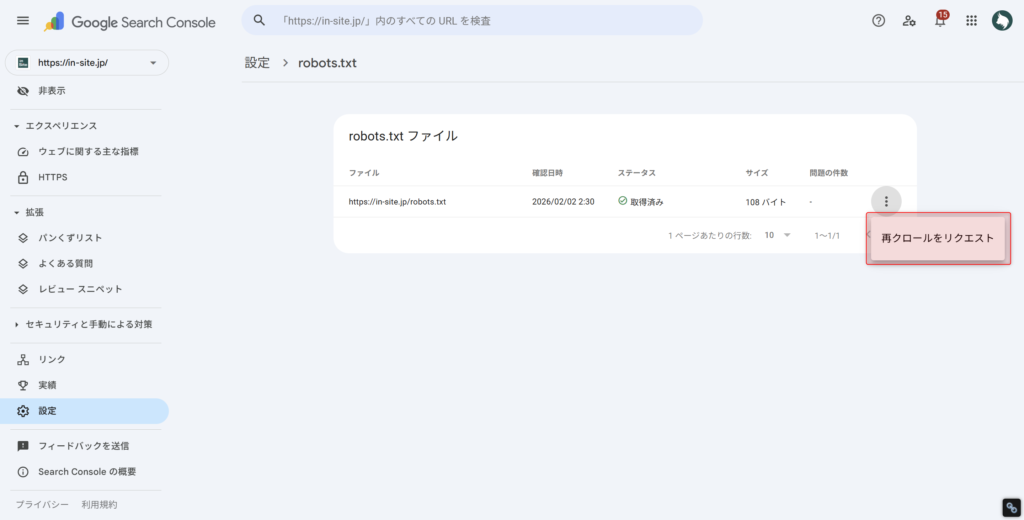
User-agent: *サーチコンソールでrobots.txtの再クロールを実施しましょう。
「設定タブ」内の「robots.txt」から「レポートを開く」をクリックし、robots.txtのURL右側の「︙(三点リーダ)」をクリックしてください。
その後「再クロールをリクエスト」をクリックすれば、robots.txtが再クロールされます。
次にサーチコンソールでURL検査を行い、「インデックス登録をリクエスト」してください。
Googleはrobots.txtの内容を最大24時間キャッシュします。変更がすぐに反映されないこともあるため、焦らず数日間は様子を見ましょう。
robots.txtの記述方法については、Google公式: robots.txtの作成と送信も参考にしてみてください。
インデックスから除外したい場合の手順
検索結果から除外したいページがインデックスされている場合は、以下の手順で対処しましょう。
まずは、robots.txtのDisallowから該当ページのURLを削除しましょう。
# 修正前
User-agent: *
Disallow: /example-page/
# 修正後(該当行を削除)
User-agent: *サーチコンソールでrobots.txtの再クロールを実施しましょう。
「設定タブ」内の「robots.txt」から「レポートを開く」をクリックし、robots.txtのURL右側の「︙(三点リーダ)」をクリックしてください。
その後「再クロールをリクエスト」をクリックすれば、robots.txtが再クロールされます。
なお、Googleはrobots.txtの内容を最大24時間キャッシュします。変更がすぐに反映されないこともあるため、焦らず数日間は様子を見ましょう。
HTMLの<head>内にメタタグを追加します。
<meta name="robots" content="noindex">または、HTTPレスポンスヘッダーで設定することも可能です。
X-Robots-Tag: noindexURL検査ツールからインデックス登録リクエストを行い、Googlebotがクロールしてnoindexを認識するのを待ちましょう。
期間を置いて、Search ConsoleのURL検査ツールで「noindexが検出されました」と表示されることを確認しましょう。
ここで最も重要なポイントが、robots.txtのDisallowを解除した状態でnoindexタグを設定することです。robots.txtでブロックしたままnoindexを設定しても、Googlebotがページにアクセスできず、noindexタグを読み取れません。
Google公式ドキュメントにも、次のとおり記載されています。
"For the noindex rule to be effective, the page or resource must not be blocked by a robots.txt file"
(和訳)
noindexルールを有効にするためには、そのページやリソースがrobots.txtによってブロックされていない必要があります。
必ずrobots.txtのDisallowから該当ページを削除したうえで、noindexタグを設定するようにしましょう。
robots.txtとnoindexの違いと正しい使い分け

robots.txtはクロール制御、noindexはインデックス制御。この違いを押さえておけば、今後同じような問題で迷うことはなくなります。
| 項目 | robots.txt | noindex |
|---|---|---|
| 目的 | クロールの制御(アクセスを許可/拒否) | インデックスの制御(検索結果への表示を防止) |
| 制御対象 | クローラーのページアクセス | 検索エンジンによるインデックス登録 |
| 設定場所 | サイトルートの robots.txt ファイル | HTML <head> 内のメタタグ or HTTPヘッダー |
| インデックス防止 | できない(URLだけでインデックスされる場合がある) | できる |
| 併用時の注意 | robots.txtでブロックしたままだとnoindexが読み取れない。必ずクロールを許可したうえでnoindexを設定する | |
robots.txtでブロックしたままnoindexを設定しても、Googlebotがページにアクセスできないためnoindexタグは認識されません。検索結果から除外したい場合は、必ずrobots.txtのブロックを解除してからnoindexを設定してください。
使い分けの判断基準は、目的によって異なります。
- 検索結果から除外したい
→ noindexを使う - クローラーの負荷を減らしたい
→ robots.txtを使う(大規模サイト向け) - 両方の目的がある
→ noindexを設定し、robots.txtのブロックは解除する
そのページの役割や目的に合わせて、必要な対応を選択するようにしましょう。
その他のインデックスステータス一覧
その他のインデックスステータスの一覧を以下の表にまとめました。他のエラーや除外が発生している方は参考にしてください。
| 大分類 | カテゴリ | ステータス名 | 対処の必要性 |
|---|---|---|---|
| 登録済み | – | ページはインデックスに登録済みです | 不要 |
| 警告あり | robots.txtによりブロックされましたが、インデックスに登録しました | 確認推奨 | |
| コンテンツのない状態でページがインデックスに登録されています | 確認推奨 | ||
| 未登録 | エラー | サーバーエラー(5xx) | 高い |
| リダイレクトエラー | 高い | ||
| 未承認のリクエスト(401)が原因でブロックされました | 高い | ||
| アクセス禁止(403)が原因でブロックされました | 高い | ||
| 見つかりませんでした(404) | 状況による | ||
| 他の 4xx の問題が原因で、URL がブロックされました | 高い | ||
| ソフト404 | 高い | ||
| ブロック | robots.txt によりブロックされています。 | 意図的なら不要 | |
| URL に noindex が指定されています | 意図的なら不要 | ||
| クロール・Google判断 | 検出 – インデックス未登録 | 中程度 | |
| クロール済み – インデックス未登録 | 高い | ||
| 重複・正規化 | 代替ページ(適切なcanonicalタグあり) | 不要 | |
| 重複しています。ユーザーにより、正規ページとして選択されていません | 確認推奨 | ||
| 重複しています。Google により、ユーザーがマークしたページとは異なるページが正規ページとして選択されました | 確認推奨 | ||
| ページにリダイレクトがあります | 不要 |
なお、全ステータスについて詳しく解説している「インデックスカバレッジとは?全ステータスの意味と対処法を解説」も参考にしてください。
また、インデックスに登録されないページ数を確認する方法は、「「インデックスに登録されていないページ数」の確認方法と対処法【放置OKなケースも解説】」を参考にしてください。
まとめ
「robots.txtによりブロックされましたが、インデックスに登録しました」についての要点は以下のとおりです。
- robots.txtはクロール制御でありインデックス制御ではない
- 外部リンク経由でURLだけがインデックスされることが原因
- 対処の要否は「そのページをインデックスさせたいか」で判断する
- 除外したい場合はrobots.txtのブロックを解除してからnoindexを設定する
- robots.txt変更後の反映には最大24時間かかる
GoogleのGary Illyesが述べた「robots.txtはクロール用、メタタグはインデックス用」という原則を押さえておけば、類似の問題にも迷わず対処できるでしょう。
まずはSearch Consoleを開いて、自サイトで該当するURLがないか確認してみてください。
\ インデックス管理を自動化 /
inSite(インサイト)
サイト内ページのインデックス状態を毎日自動でチェック。robots.txtブロックの影響やnoindex設定の漏れも一目で把握できます。
1ページずつURL検査をしなくても、インデックス状態を常に監視。効率よくSEO施策を進められます。
無料で試してみる ↗