「未承認のリクエスト(401)が原因でブロックされました」とは、Googlebotがページにアクセスした際に認証(パスワード等)を求められ、それを通過できずにインデックス登録がブロックされた状態を指します。
このエラーが表示されたページは、認証を解除しない限りGoogle検索の結果に表示されません。 ただし、会員限定ページや管理画面など、もともとインデックスさせる必要がないページであれば、対処せず放置しても問題ないケースも多くあります。
この記事では、対処が必要かの判断基準と、Basic認証・htaccess等の原因別対処法を解説します。
\ インデックス管理を自動化 /
inSite(インサイト)
サイト内のページのクロール状態を毎日自動でチェック。どれだけのページがインデックスされてなくて原因は何なのか、クローラーは定期的に来ているのかといった情報を常に監視できます。
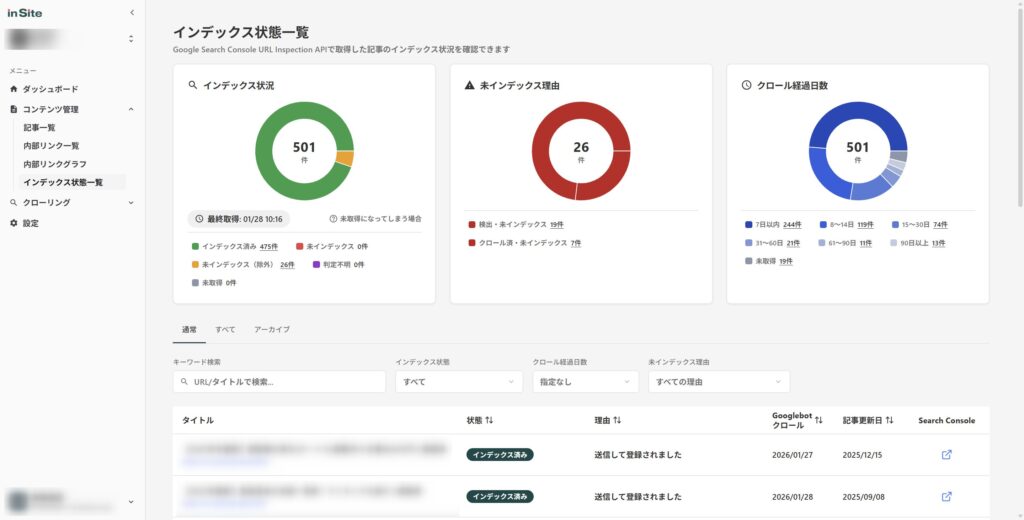
1ページずつURL検査をしなければわからないインデックス状態を常に把握でき、効率よくSEOの打ち手を考えることができます。
無料で試してみる ↗「未承認のリクエスト(401)が原因でブロックされました」とは?
「未承認のリクエスト(401)が原因でブロックされました」は、Googlebotがあなたのサイトのページにアクセスしようとした際に「認証が必要です」とサーバーから拒否された状態を意味します。つまり、パスワードで保護されたページにGooglebotが入れなかった、ということです。
Google公式ヘルプでは、次のように説明されています。
このページへのアクセスには認証が必要なため、Googlebotのアクセスがブロックされています(401レスポンス)
HTTPの仕様においても、401は「認証情報がないためアクセスを拒否した」ことを示すステータスコードです。(HTTP 401 Unauthorized – MDN Web Docs) Googlebotはパスワードを入力できないため、認証が必要なページは必ずブロックされます。
Search Consoleの「ページのインデックス登録」レポートでは、このステータスは「未登録」カテゴリに分類されています。
401以外にも多くのステータスが存在するため、全体像を把握したい場合は「インデックスカバレッジの全ステータス一覧」もあわせてご確認ください。
「未承認のリクエスト(401)が原因でブロックされました」の確認方法
自社サイトで401エラーが発生しているかどうかは、Search Consoleの複数の機能から確認できます。 ここでは、実務でよく使う3つの確認方法を紹介します。
Search Consoleの左メニューから「ページ」(旧「カバレッジ」)を開きましょう。
「ページがインデックスに登録されなかった理由」の一覧に「未承認のリクエスト(401)が原因でブロックされました」が表示されていれば、該当するURLが存在しています。
クリックすると、対象URLの一覧を確認できます。
特定のURLについて401が返されているか確認したい場合は、Search Console上部の検索バーにURLを入力してURL検査を実行しましょう。
「ページのインデックス登録」欄に401関連のステータスが表示されていれば、そのURLが該当しています。
Google公式が推奨しているシンプルな方法があります。
ブラウザのシークレットモード(プライベートウィンドウ)で該当URLにアクセスしてみてください。
認証ダイアログ(ユーザー名とパスワードの入力画面)が表示されれば、Googlebotも同様にブロックされていると判断できます。
さらに詳しい確認手順については、Google公式の「クロールエラーのトラブルシューティング – Google Developers」も参考になります。
401エラーが発生する6つの原因
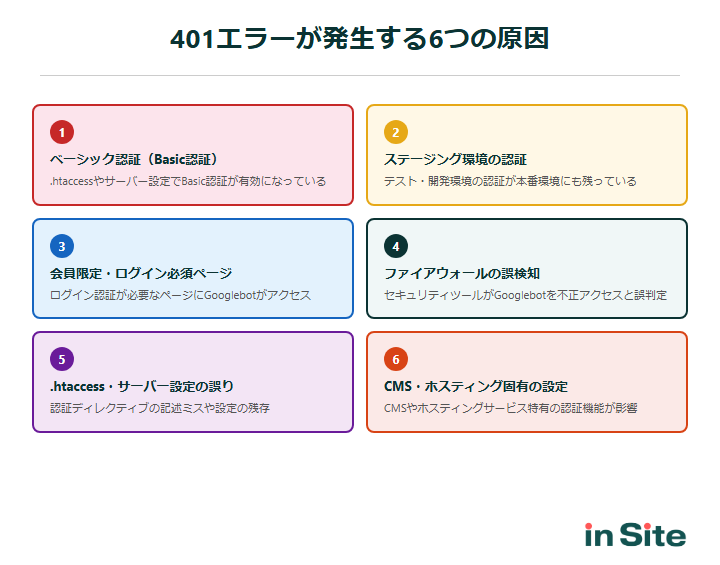
401エラーの原因は「ベーシック認証」だけではありません。実際にはさまざまなパターンが存在し、原因を正確に特定することが適切な対処への第一歩となります。ここでは、代表的な6つの原因を紹介します。
ベーシック認証(Basic認証)で保護されたページ
401エラーが発生する原因として最も多いのがベーシック認証(Basic認証)で保護されたページであるパターンです。 .htaccessと.htpasswdを使ったHTTP認証(いわゆるベーシック認証)でページを保護している場合、Googlebotは認証情報を提供できないためブロックされます。
Google Search Consoleヘルプコミュニティでは、約1万ページにベーシック認証を設定した結果、全ページが一括で401ステータスになった事例も報告されています。 ※参考: ベーシック認証と401エラーに関するGoogle公式コミュニティの議論
サイトリニューアル中に一時的にベーシック認証をかけたまま解除を忘れる、というケースも珍しくありません。
ステージング環境・テスト環境の認証設定
401エラーが発生する2つ目の原因が、開発やテスト用のステージング環境にベーシック認証を設定しているケースです。
staging.example.comのようなサブドメインがSearch Consoleに登録されていると、そこで401が検出されることがあります。
特に注意したいのが、ステージング環境から本番環境へ移行する際の認証設定の解除漏れです。 環境移行時のチェックリストに「認証設定の確認」を含めておくと安心でしょう。
会員限定・ログイン必須ページ
401エラーが発生する3つ目の原因が、会員限定・ログイン必須ページです。
会員ダッシュボードやマイページ、オンラインコースの受講画面など、ログイン後にのみアクセスできるページも401の原因になります。 WordPressの管理画面(/wp-admin/)が対象になるケースも少なくありません。
ただし、これらのページはそもそもインデックスさせる必要がないことがほとんどです。 後述する「放置してよいケース」に該当する可能性が高いため、慌てて対処する必要はないでしょう。
ファイアウォール・セキュリティツールの誤検知
401エラーが発生する4つ目の原因が、Cloudflare、Sucuri、WordfenceといったWAF(Web Application Firewall)やセキュリティプラグインが、Googlebotを不正アクセスと誤判定してブロックしてしまうケースです。
GoogleのJohn Mueller氏も、CDNが原因で401や403が発生するケースがあると指摘しています。 セキュリティツールを導入した直後に401エラーが増えた場合は、この原因を疑ってみてください。
.htaccessやサーバー設定の誤設定
401エラーが発生する5つ目の原因が、IP制限の設定ミスでGooglebotのIPレンジがブロックされていたり、.htpasswdによるディレクトリ保護が意図しない範囲に適用されていたりするケースです。
Google公式でも「ファイアウォールやDoS対策の保護システムがGooglebotをブロックする可能性がある」と警告しています。
サーバー設定に不慣れな場合は、エンジニアやサーバー管理者に「Googlebotが401でブロックされている可能性があるので、.htaccessとIP制限の設定を確認してほしい」と伝えてみましょう。
CMS・ホスティングサービス固有の設定
401エラーが発生する6つ目の原因が、SquarespaceやWixの「工事中モード」、Kinstaのステージング機能など、CMSやホスティングサービスが提供する機能が自動的に認証を設定するケースです。
レンタルサーバーの管理画面から設定したアクセス制限が原因になっていることもあるでしょう。
サーバーやCMSの管理画面で「アクセス制限」「メンテナンスモード」「パスワード保護」といった設定項目がオンになっていないか、一度確認してみることをおすすめします。
対処が必要なケースと放置してよいケースの判断基準
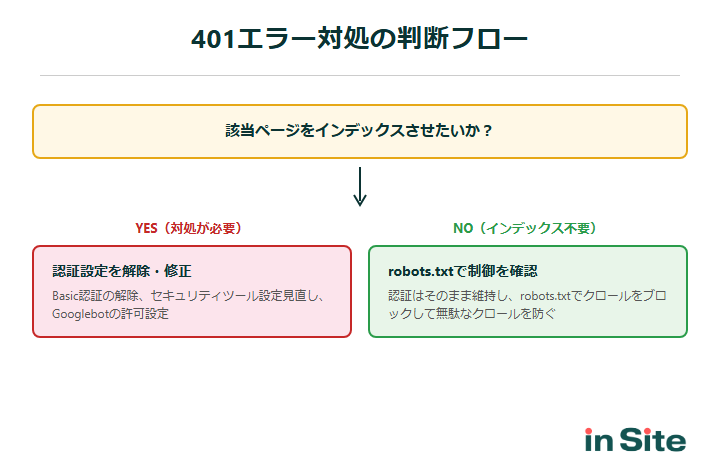
401エラーが表示されたからといって、すべてのケースで対処が必要なわけではありません。 「対処すべきか、放置してよいか」を正しく判断することが、限られたリソースを有効に使うための鍵になります。
- 検索結果に表示させたい(インデックスさせたい)ページが401でブロックされている
- 本番環境で意図せずベーシック認証やIP制限が残っている
- セキュリティツールの誤検知でGooglebotがブロックされている
- サイトマップに含まれているURLが401を返している(Search Consoleで「エラー」に分類される)
- 意図的に認証をかけているページ(会員限定ページ、管理画面、ステージング環境など)
- そもそもインデックスさせる必要がないページ
判断の流れはシンプルです。
まず「401が出ているページはインデックスさせたいか?」と自問してください。Yesなら対処が必要です。
Noなら、次に「robots.txtでDisallowを設定しているか?」を確認します。 設定済みならそのまま放置してOK。未設定なら、robots.txtにDisallowルールを追加してクロールバジェットの浪費を防ぎましょう。
放置してよいケースでも、robots.txtでDisallowを設定しておくことで、Googlebotが無駄に401ページをクロールする回数を減らせます。大規模サイトほど、この設定がクロール効率に影響してきます。
自社サイトのインデックス状況を効率的に把握したい方は、inSiteを使えば簡単に管理・確認できます。
具体的な対処法
原因が特定できたら、次は実際に修正を行いましょう。 ここでは、原因パターン別の具体的な対処手順を解説します。
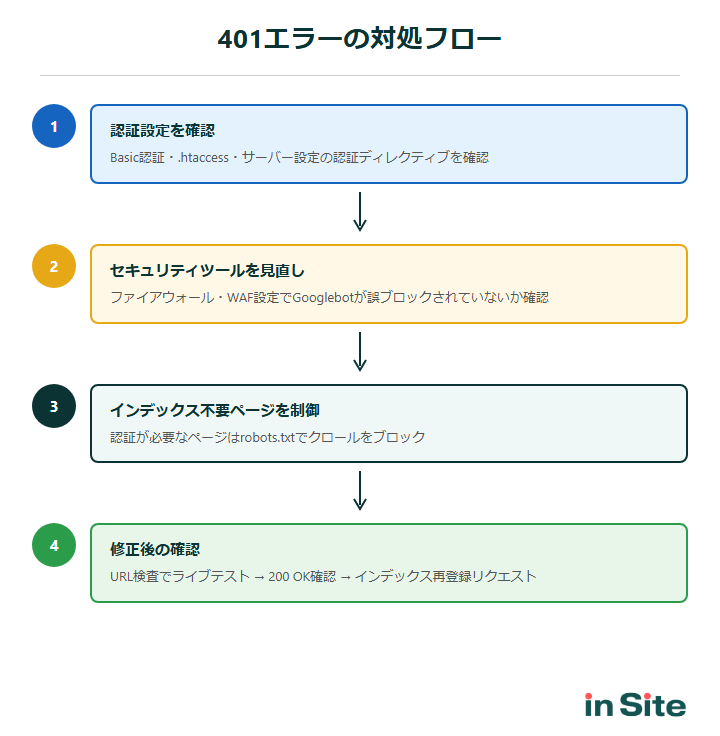
ベーシック認証の解除手順
最も一般的な原因であるベーシック認証の解除方法は以下のとおりです。
サーバー上の該当ディレクトリにある.htaccessファイルを開き、以下のような認証設定がないか確認します。
AuthType Basic
AuthName "Restricted Area"
AuthUserFile /path/to/.htpasswd
Require valid-userインデックスさせたいページの場合、上記の記述を削除するか、先頭に「#」をつけてコメントアウトします。
# AuthType Basic
# AuthName "Restricted Area"
# AuthUserFile /path/to/.htpasswd
# Require valid-userファイルを保存した後、シークレットモードで該当ページにアクセスし、認証ダイアログが表示されないことを確認してください。
Google公式では「認証機能を使ったページの保護を削除するか、Googlebotからのアクセスであることを確認して、ページへのアクセスを許可します」と案内しています。
ただし、認証が本当に不要なページかどうかを必ず確認してから解除するようにしましょう。セキュリティ上の理由で認証をかけているページの認証を安易に外すのは危険です。
セキュリティツール・ファイアウォールの設定見直し
WAFやセキュリティプラグインがGooglebotをブロックしている場合の対処法です。
GooglebotのUser-Agentをホワイトリストに追加する
Cloudflare、Sucuri、Wordfenceなどのセキュリティツールの管理画面で、GooglebotのUser-Agentを許可リスト(ホワイトリスト)に追加します。
設定場所はツールによって異なりますが、「ファイアウォールルール」や「IPアクセス制御」の画面に設定項目があることが多いでしょう。
Googlebotの正当性を確認する
ホワイトリストに追加する前に、アクセスが本当にGooglebotからのものか確認することも大切です。
リバースDNSルックアップで、アクセス元IPが「googlebot.com」または「google.com」ドメインに解決されるか検証できます。
Google公式でも「Googlebotは人間のユーザーよりも多数のリクエストを発することが多いため、保護システムが反応してブロックされる場合がある」と注意を促しています。
インデックス不要なページの正しい制御方法
インデックスさせる必要がないページについては、401のまま放置するのではなく、適切な制御方法を設定しておくのがベストプラクティスです。
robots.txtでDisallowを設定する
最もシンプルな方法です。robots.txtに以下のようなルールを追加し、Googlebotがそもそもクロールしないようにしましょう。
User-agent: *
Disallow: /members/
Disallow: /wp-admin/
Disallow: /staging/
クロール自体を防ぐことで、クロールバジェットの浪費を抑えられます。
robots.txtについて詳しくは「robots.txtによるブロックの対処法」を参照してください。
noindexタグとの使い分け
robots.txtはクロール自体をブロックしますが、noindexタグはクロールを許可した上でインデックスを拒否する仕組みです。
ページの内容をGoogleに認識させたくない場合はrobots.txt、ページの存在は認識させつつインデックスだけ除外したい場合はnoindexタグが適しています。
noindexタグの詳細は「noindexタグによる除外の対処法」で解説しています。
重要な注意点として、GoogleのGary Illyes氏は「robots.txtが4xxを返すと、存在しないものとして扱われる」と警告しています。
robots.txt自体がベーシック認証で保護されていると、Googleはすべてのクロールを停止してしまう可能性があります。robots.txtファイルが認証なしでアクセスできることを必ず確認してください。
※参考: Don’t use 403s or 404s for rate limiting – Google Search Central Blog
修正後の確認とインデックス再リクエスト
認証を解除した後は、以下の手順で修正が正しく反映されたか確認しましょう。
ブラウザのシークレットモードで該当ページにアクセスし、認証ダイアログが表示されずにページが正常に閲覧できることを確認しましょう。
Search ConsoleのURL検査ツールに該当URLを入力し、「インデックス登録をリクエスト」ボタンをクリックしましょう。
これにより、Googlebotに再クロールを促すことができます。
401エラーが複数のURLで発生していた場合は、「ページのインデックス登録」レポートで該当ステータスを選択し、「修正を検証」ボタンから一括検証を実行できます。
なお、Matt Cutts氏の発言によると、Googleは401を初めて返したページに対して24時間の「保護期間」を設ける場合があるとされています。
そのため、修正してもすぐには反映されないことがあります。焦らず数日〜数週間は様子を見てみてください。
修正後のインデックス状態を継続的にモニタリングするなら、inSiteが便利です。また、「インデックス状態を自動チェックするツール」の記事もあわせて参考にしてください。
401エラーのSEOへの影響
401エラーを放置しても、サイト全体の検索順位が壊滅的なダメージを受けることは基本的にありません。
ただし、対象ページはインデックスから除外され、大量の401ページが存在する場合はクロールバジェットにも悪影響を及ぼします。Google公式見解をもとに、具体的な影響を見ていきましょう。

Googleは401をどう処理するか
Google公式ドキュメントによると、4xxエラー(429を除く)はすべて同じ扱いを受けるとされています。
「All 4xx errors, except 429, are treated the same」と明記されており、401も403も404も、Google検索における処理は基本的に同じです。
具体的には以下のような影響があります。
- すでにインデックスされているURLは、インデックスから削除される
- 新たに発見された401ページは処理されない
- 該当URLへのクロール頻度は徐々に低下する
重要な点として、401をクロールレート制限の手段として使用してはいけません。 Google公式がこの行為を明確に警告しています。
※出典: HTTPステータスコードがGoogleのクローラーに与える影響 – Google Developers
クロールバジェットへの影響
401ページへのクロールはクロールバジェットを消費します。 大量の401ページが存在する場合、他の重要ページがクロールされる機会を奪ってしまう可能性があるわけです。
インデックス不要なページにはrobots.txtでDisallowを設定して、クロールバジェットの浪費を防ぐのがおすすめの方法です。 加えて、内部リンクが401ページに向いている場合、リンクエクイティ(リンクの評価価値)も失われてしまいます。不要なリンクの整理もあわせて行うとよいでしょう。
サーバー側のエラーについて知りたい方は「サーバーエラー(5xx)の確認方法と対処法」も参考にしてください。
401と403の違い
401と403はどちらもアクセスが拒否される点では似ていますが、技術的な意味合いが異なります。
| 大分類 | カテゴリ | ステータス名 | 対処の必要性 |
|---|---|---|---|
| 登録済み | – | ページはインデックスに登録済みです | 不要 |
| 警告あり | robots.txtによりブロックされましたが、インデックスに登録しました | 確認推奨 | |
| コンテンツのない状態でページがインデックスに登録されています | 確認推奨 | ||
| 未登録 | エラー | サーバーエラー(5xx) | 高い |
| リダイレクトエラー | 高い | ||
| 未承認のリクエスト(401)が原因でブロックされました | 高い | ||
| アクセス禁止(403)が原因でブロックされました | 高い | ||
| 見つかりませんでした(404) | 状況による | ||
| 他の 4xx の問題が原因で、URL がブロックされました | 高い | ||
| ソフト404 | 高い | ||
| ブロック | robots.txt によりブロックされています。 | 意図的なら不要 | |
| URL に noindex が指定されています | 意図的なら不要 | ||
| クロール・Google判断 | 検出 – インデックス未登録 | 中程度 | |
| クロール済み – インデックス未登録 | 高い | ||
| 重複・正規化 | 代替ページ(適切なcanonicalタグあり) | 不要 | |
| 重複しています。ユーザーにより、正規ページとして選択されていません | 確認推奨 | ||
| 重複しています。Google により、ユーザーがマークしたページとは異なるページが正規ページとして選択されました | 確認推奨 | ||
| ページにリダイレクトがあります | 不要 |
なお、全ステータスについて詳しく解説している「インデックスカバレッジとは?全ステータスの意味と対処法を解説」も参考にしてください。
また、インデックスに登録されないページ数を確認する方法は、「「インデックスに登録されていないページ数」の確認方法と対処法【放置OKなケースも解説】」を参考にしてください。
まとめ
「未承認のリクエスト(401)が原因でブロックされました」への対応ポイントを振り返りましょう。
- Googlebotが認証を通過できずインデックス登録がブロックされた状態
- 認証を解除しない限りGoogle検索結果には表示されない
- 会員限定ページや管理画面なら対処不要で放置してよい
- Basic認証・htaccess・ステージング環境などが主な原因
- 対処が必要か放置してよいかの判断基準と具体的な対処法を解説
まずはSearch Consoleで自社サイトの401エラー対象ページを確認し、対処が必要か放置してよいかを判断してみてください。
401エラーを解消してもインデックスされない場合は、別の原因が考えられます。以下の関連記事も参考にしてください。
\ インデックス管理を自動化 /
inSite(インサイト)
サイト内のページのクロール状態を毎日自動でチェック。どれだけのページがインデックスされてなくて原因は何なのか、クローラーは定期的に来ているのかといった情報を常に監視できます。
1ページずつURL検査をしなければわからないインデックス状態を常に把握でき、効率よくSEOの打ち手を考えることができます。
無料で試してみる ↗