robots.txtとは、検索エンジンのクローラーに対して「どのページをクロールしてよいか」を伝えるテキストファイルです。サイトのルートディレクトリに配置することで、Googlebot等のクローラーがサイトを巡回する際の指示書として機能します。
「robots.txtって何を書けばいいの?」「設定を間違えたらインデックスされなくなる?」「AIクローラーもブロックできるの?」。robots.txtに関する疑問は多いですが、基本を理解すれば設定はシンプルです。
筆者はインハウスSEO担当として、数万ページ規模の求人サイトでテクニカルSEOを管理していました。大規模サイトではクロールバジェットの最適化が重要で、robots.txtの設定ミス一つでサイト全体のインデックスに影響が出ることを何度も経験しています。特に2026年現在は、GPTBotやClaudeBotなどAIクローラーへの対応も必須になっており、robots.txtの重要性はさらに高まっています。
この記事では、robots.txtの基本的な書き方から配置場所、無料ツールでの確認方法、よくある間違い、そしてAIクローラー対応まで、実務で必要な知識を網羅的に解説します。
\ テクニカルSEOの管理を効率化 /
robots.txtとは?役割と仕組みをわかりやすく解説
robots.txt(ロボッツテキスト)は、Webサイトのルートディレクトリに配置するテキストファイルで、検索エンジンのクローラーに対して「このページはクロールしてOK」「このページはクロールしないで」と伝える役割を持ちます。
robots.txtの基本的な仕組み
クローラーがサイトを訪問するとき、最初に https://example.com/robots.txt を確認します。このファイルに書かれた指示に従って、クロール対象のページを判断します。
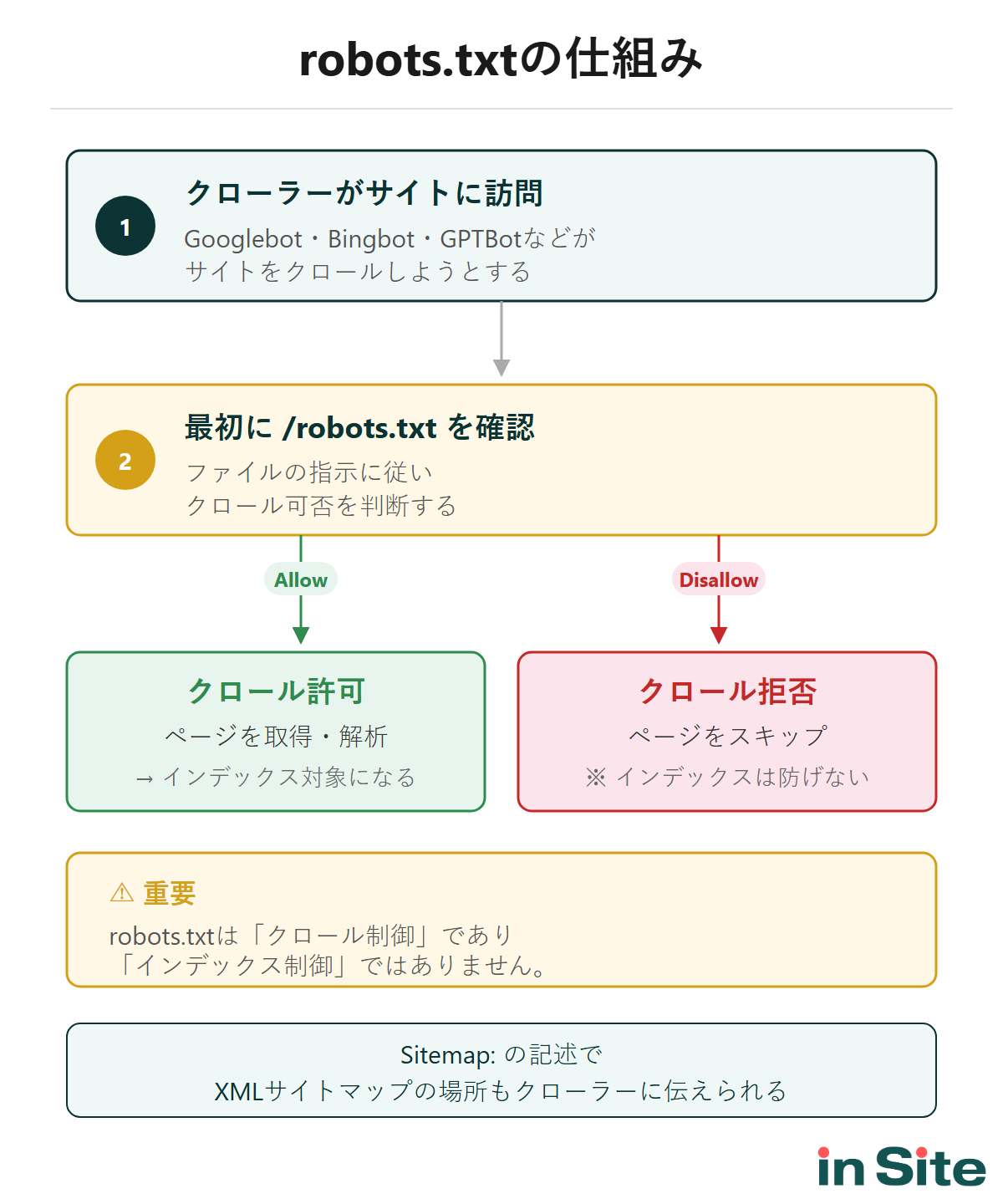
- クロール制御が目的
robots.txtはクローラーのアクセスを制御するもの。インデックス登録を直接ブロックする機能はない - あくまで「お願い」
GooglebotやBingbotは従うが、悪意のあるボットは無視する可能性がある - ドメイン単位で機能する
サブドメインには別のrobots.txtが必要(example.comとblog.example.comは別管理)
robots.txtが必要なケース・不要なケース
すべてのサイトにrobots.txtが必須というわけではありません。
| ケース | robots.txtの必要性 | 理由 |
|---|---|---|
| 大規模サイト(数千ページ以上) | 必須 | クロールバジェットの最適化が重要。不要なページへのクロールを制限する必要がある |
| WordPress等のCMS | 推奨 | 管理画面(/wp-admin/)やフィード等、クロール不要なURLが多い |
| 開発・ステージング環境 | 必須 | 本番公開前のサイトをクローラーに見せないようにする |
| 小規模な静的サイト | 任意 | 全ページクロールされても問題なければ不要。Sitemapの指定だけでも有効 |
筆者が管理していた求人サイトでは、数万ページの中に検索結果ページやフィルタリングページが大量にありました。これらをrobots.txtでクロール制限しないと、クロールバジェットが無駄に消費され、本当にインデックスしてほしいページのクロール頻度が下がるという問題が起きていました。
robots.txtの書き方(基本ルールと記述例)
robots.txtの書き方はシンプルですが、ルールを間違えるとサイト全体のクロールに影響します。基本構文を押さえたうえで、サイトの規模や用途に合ったパターンを選びましょう。
基本構文(User-agent / Disallow / Allow / Sitemap)
robots.txtで使う主要なディレクティブは4つです。
| ディレクティブ | 意味 | 記述例 |
|---|---|---|
| User-agent | 対象のクローラーを指定 | User-agent: Googlebot |
| Disallow | クロールを禁止するパスを指定 | Disallow: /admin/ |
| Allow | Disallow内で例外的に許可するパスを指定 | Allow: /admin/public/ |
| Sitemap | XMLサイトマップのURLを指定 | Sitemap: https://example.com/sitemap.xml |
基本的な記述例を示します。
# すべてのクローラーに対する指示
User-agent: *
Disallow: /admin/
Disallow: /tmp/
Allow: /
# サイトマップの場所
Sitemap: https://example.com/sitemap.xml
- 大文字・小文字を区別する
Disallowは正しいがdisallowは仕様上は許容されるものの、統一を推奨 - 各グループは空行で区切る
User-agentとそのルールの間に空行を入れない。グループ間には空行を入れる - パスの末尾スラッシュに注意
Disallow: /adminは/admin-pageもマッチする。ディレクトリ指定なら/admin/とする - ファイルはUTF-8で保存
BOM付きUTF-8やShift-JISだと正しく認識されない場合がある
よく使うパターン別の記述例
実務でよく使うrobots.txtのパターンをまとめます。
サイト全体をクロール許可(最小構成)
User-agent: *
Allow: /
Sitemap: https://example.com/sitemap.xml
WordPress向けの標準設定
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Disallow: /wp-includes/
Disallow: /?s=
Disallow: /search/
Sitemap: https://example.com/sitemap.xml
大規模サイト向け(クロールバジェット最適化)
User-agent: *
Disallow: /search/
Disallow: /filter/
Disallow: /tag/
Disallow: /page/
Disallow: /*?sort=
Disallow: /*?page=
Sitemap: https://example.com/sitemap.xml
配置場所とファイル作成方法
robots.txtは必ずドメインのルートディレクトリ直下に配置します。
- 正しい:
https://example.com/robots.txt - 間違い:
https://example.com/blog/robots.txt(サブディレクトリは無効) - サブドメインは別ファイル:
https://blog.example.com/robots.txt - HTTPSとHTTPは別: HTTPSサイトなら
https://のrobots.txtが参照される
- テキストエディタで新しいファイルを作成
- ファイル名を
robots.txtにする(拡張子を間違えない) - UTF-8(BOMなし)で保存
- サーバーのルートディレクトリにアップロード
https://あなたのドメイン/robots.txtにアクセスして表示を確認
WordPressの場合は、テーマやSEOプラグイン(Yoast SEO、All in One SEOなど)がrobots.txtを自動生成する機能を持っています。プラグインの管理画面から編集するのが安全です。
robots.txtの確認方法(無料ツールで構文チェック)
robots.txtを作成・変更したら、必ず構文に問題がないか確認しましょう。意図したとおりにクロール制御されているかを検証する方法を紹介します。
ブラウザで直接確認する(/robots.txt)
最もシンプルな確認方法は、ブラウザのアドレスバーに直接URLを入力することです。
https://あなたのドメイン/robots.txt
これで現在のrobots.txtの内容がテキストで表示されます。競合サイトのrobots.txtも同じ方法で確認できるので、上位サイトがどのような設定をしているかを参考にできます。
inSite robots.txtテスターで構文チェック
無料ツール inSite robots.txtテスター - 構文チェック&クロール判定 →inSiteのrobots.txtテスターでは、robots.txtの内容を貼り付けるだけで以下を確認できます。
- 構文エラーの検出
ディレクティブの誤記やフォーマットの問題を指摘 - URL別のクロール判定
特定のURLが「Allowed」か「Disallowed」かをシミュレーション - User-agent別の確認
Googlebot、Bingbot、GPTBotなどクローラー別の挙動をチェック
Google Search Consoleで影響を確認する
Search Consoleでは、robots.txtの影響をインデックスの観点から確認できます。
URL検査ツール
Search Consoleの「URL検査」で特定のURLを入力すると、robots.txtによってブロックされているかどうかがわかります。「クロールを許可?」の項目で「いいえ: robots.txtによりブロック」と表示された場合は、robots.txtの設定を見直す必要があります。
インデックスカバレッジレポート
「ページ」レポート(旧カバレッジレポート)で「robots.txtによりブロック」というステータスが表示されるページがないかを確認しましょう。意図せずブロックしているページがあれば、robots.txtの修正が必要です。
その他の無料ツール
| ツール名 | 特徴 | 用途 |
|---|---|---|
| Screaming Frog(無料版) | 500URLまで無料でクロール可能 | robots.txtの影響を実際のクロールで確認 |
| Google Rich Results Test | レンダリング結果を表示 | robots.txtでリソースがブロックされていないか確認 |
| Merkle robots.txt Tester | オンラインで即チェック | URLとrobots.txtを入力してクロール可否を確認 |
robots.txtとnoindexの違い・使い分け
robots.txtとnoindexは混同されやすいですが、目的と仕組みがまったく異なります。ここを間違えると、「ブロックしたはずのページが検索結果に出ている」といったトラブルが起きます。
| 比較項目 | robots.txt | noindex |
|---|---|---|
| 目的 | クロールの制御 | インデックスの制御 |
| 仕組み | クローラーのアクセス自体をブロック | クロールは許可するが、インデックスに登録しない |
| 設置場所 | ルートディレクトリのrobots.txt | HTMLの<meta>タグ or HTTPヘッダー |
| 検索結果への影響 | URLが検索結果に表示される可能性あり(外部リンク経由) | 確実に検索結果から除外 |
| ページ単位の制御 | パス単位(ディレクトリ・ワイルドカード) | ページ単位で個別に設定 |
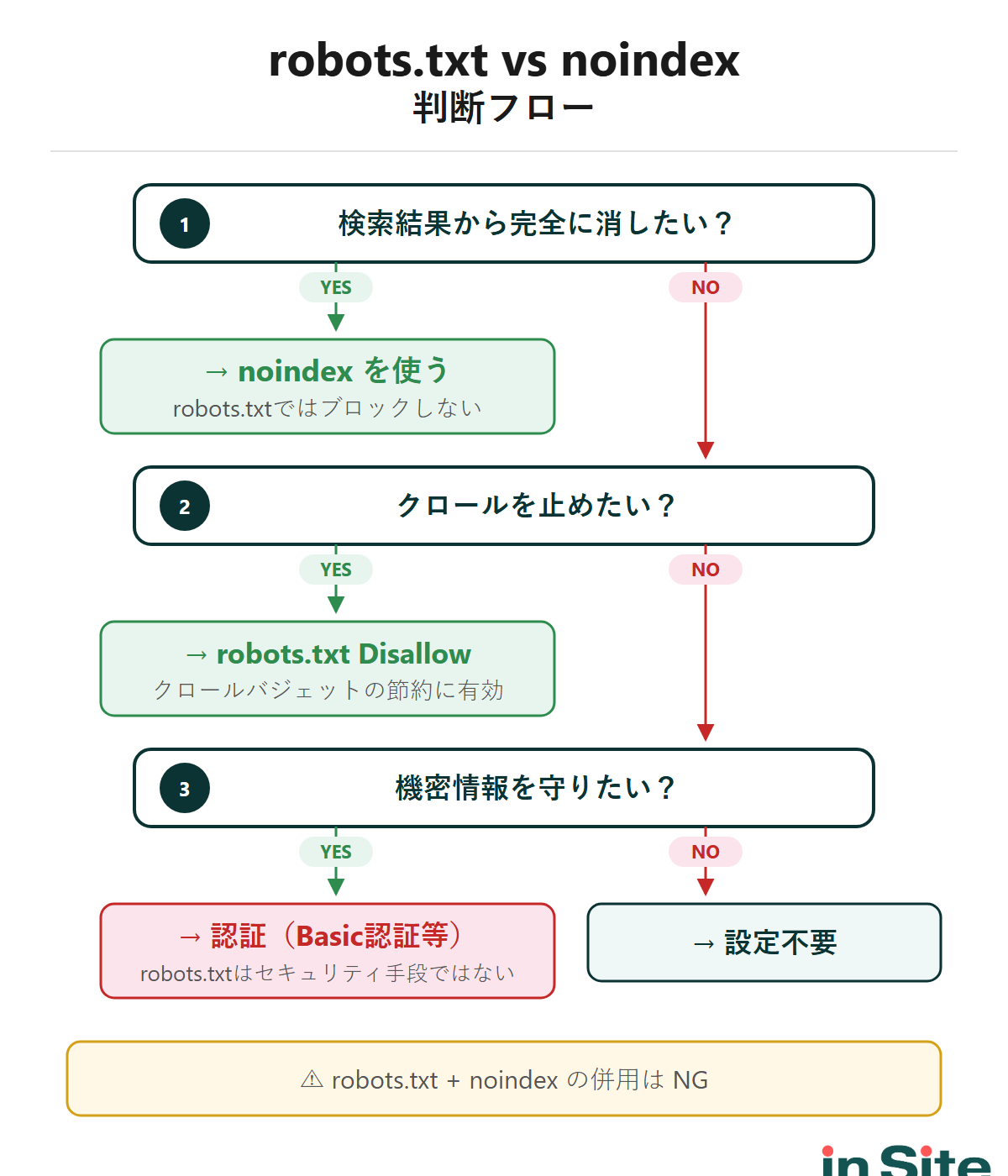
- robots.txtでDisallowすれば検索結果に出なくなる → 間違い
外部サイトからリンクされている場合、robots.txtでブロックしてもURL自体は検索結果に表示されることがある(タイトルやスニペットがない状態で表示される) - robots.txtでブロックしたページにnoindexを追加 → 効果なし
クローラーがページにアクセスできないため、noindexタグを読み取れない。両方設定するのは矛盾する
- 検索結果から完全に消したい
noindexを使う(robots.txtでブロックしない) - クロールバジェットを節約したい
robots.txtでDisallow - 機密情報を守りたい
そもそも認証(Basic認証等)を設定する。robots.txtはセキュリティ手段ではない
robots.txtでよくある間違い5つ
筆者が実務で見てきた、robots.txtの典型的な間違いを紹介します。
間違い1: インデックスを防げると思っている
最も多い間違いです。「このページを検索結果に出したくない」という理由でrobots.txtにDisallowを追加するケースですが、前述のとおりrobots.txtではインデックスを確実に防ぐことはできません。
検索結果から除外したい場合は、noindexメタタグを使いましょう。
間違い2: CSS・JavaScriptをブロックしてしまう
WordPressなどで /wp-includes/ をまるごとDisallowすると、CSSやJavaScriptファイルへのクローラーのアクセスもブロックされます。Googleはページをレンダリングして内容を評価するため、レンダリングに必要なリソースがブロックされるとSEO評価に悪影響が出ます。
# NG例
User-agent: *
Disallow: /wp-includes/
# OK例(管理画面のみブロック)
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
間違い3: テスト環境の設定を本番に持ち込む
開発・ステージング環境では Disallow: / を設定するのが一般的ですが、本番公開時にこの設定を解除し忘れるケースがあります。
# 本番環境にこれが残っていると全ページクロール拒否
User-agent: *
Disallow: /
筆者も過去に、ステージング環境から本番にデプロイする際にrobots.txtの設定を元に戻し忘れ、数日間サイト全体のクロールが止まった経験があります。デプロイチェックリストにrobots.txtの確認を必ず入れておきましょう。
間違い4: User-agent: * の誤解
User-agent: * は「すべてのクローラー」を意味しますが、正確には**「個別にUser-agentが指定されていないクローラー」**に適用されます。
# Googlebotには個別ルールが適用される
User-agent: Googlebot
Disallow: /private/
# Googlebot以外のクローラーにはこちらが適用
User-agent: *
Allow: /
この例では、Googlebotは /private/ にアクセスできませんが、Bingbotは User-agent: * のルールに従い、/private/ を含むすべてのページにアクセスできます。
間違い5: サブドメインを制御しようとする
robots.txtはドメイン単位で機能するため、example.com/robots.txt の設定は blog.example.com には適用されません。
# example.com/robots.txt に書いても、blog.example.com には効果なし
User-agent: *
Disallow: /blog/ # これはexample.com/blog/のみに適用
サブドメインのクロールを制御する場合は、そのサブドメインのルートに別途robots.txtを配置する必要があります。
AIクローラーをrobots.txtで制御する方法【2026年最新】
2026年現在、GPTBot、ClaudeBot、PerplexityBotなどのAIクローラーへの対応は、robots.txt設定において避けて通れないテーマになっています。AI検索(ChatGPTの検索機能、Perplexity、Google AI Overview等)に自サイトの情報を引用してもらうか、AI学習に使わせないかを、robots.txtで制御できます。
主要AIクローラー一覧と設定例
| クローラー名 | 運営元 | 目的 |
|---|---|---|
| GPTBot | OpenAI | ChatGPTの学習・検索用データ収集 |
| ChatGPT-User | OpenAI | ChatGPTのリアルタイム検索 |
| ClaudeBot | Anthropic | Claudeの学習用データ収集 |
| PerplexityBot | Perplexity | Perplexityの検索・回答生成 |
| Google-Extended | Geminiの学習用データ収集(検索インデックスとは別) | |
| Bytespider | ByteDance | TikTok関連のAI学習 |
| cohere-ai | Cohere | LLM学習用データ収集 |
AIクローラーをすべてブロックする例
# AI学習用クローラーをブロック
User-agent: GPTBot
Disallow: /
User-agent: ChatGPT-User
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: PerplexityBot
Disallow: /
User-agent: Google-Extended
Disallow: /
User-agent: Bytespider
Disallow: /
User-agent: cohere-ai
Disallow: /
AI検索に引用される設定 vs 学習拒否設定
AIクローラーへの対応は、サイトの戦略によって方針が分かれます。
| 方針 | robots.txt設定 | メリット | デメリット |
|---|---|---|---|
| AI検索に引用されたい | AIクローラーをAllow(またはブロックしない) | ChatGPT・Perplexity等で引用されトラフィック増加の可能性 | AI学習にコンテンツが使用される |
| AI学習を拒否したい | AIクローラーをDisallow | コンテンツが無断でAI学習に利用されるのを防げる | AI検索での引用機会を失う |
| 検索は許可・学習は拒否 | ChatGPT-UserはAllow、GPTBotはDisallow | AI検索での引用を維持しつつ学習利用を制限 | クローラーの区別が正確とは限らない |
OpenAIはGPTBot(学習用)とChatGPT-User(リアルタイム検索用)を公式に分けています。学習利用だけをブロックしたい場合はGPTBotのみDisallowにする方法がありますが、引用頻度への影響は未知数です。判断に迷う場合は、まず全許可で運用し、状況を見て制限を追加するのが安全です。
llms.txtとの違いと併用方法
2025年から注目されているllms.txtは、robots.txtとは異なるアプローチでAIとの関係を制御するファイルです。
| 比較項目 | robots.txt | llms.txt |
|---|---|---|
| 目的 | クロールの許可/拒否 | AIへの情報提供(サイト概要・構造の説明) |
| 対象 | 検索エンジンクローラー全般 | LLM(大規模言語モデル) |
| 内容 | Disallow/Allowルール | サイトの説明、主要ページのリスト、引用ポリシー |
| 標準化 | RFC 9309で標準化済み | 提案段階(広く採用が進行中) |
robots.txtが「入口の門番」だとすれば、llms.txtは「AIへの自己紹介状」です。両方を配置することで、クロール制御と情報提供の両面からAIとの関係をコントロールできます。
# robots.txt: AI学習クローラーはブロック、検索用は許可
User-agent: GPTBot
Disallow: /
User-agent: ChatGPT-User
Allow: /
# llms.txt: サイト概要と主要ページをAIに提供
# (llms.txtはrobots.txtとは別ファイルとして配置)
よくある質問
1つ目は、SEOプラグイン(Yoast SEO、All in One SEOなど)の管理画面から編集する方法。プラグインの「ツール」や「ファイルエディター」からrobots.txtを直接編集できます。
2つ目は、FTPやファイルマネージャーでサーバーに直接robots.txtをアップロードする方法です。WordPressはデフォルトで仮想的なrobots.txtを生成しますが、実ファイルを配置するとそちらが優先されます。
まとめ
- robots.txtはクローラーへの「指示書」。インデックス制御ではなくクロール制御が目的
- 基本構文はUser-agent・Disallow・Allow・Sitemapの4つ。書き方のパターンを例付きで解説
- 確認は/robots.txtへの直接アクセス、inSiteテスター、Search Consoleの3つが基本
- robots.txtとnoindexは目的が違う。間違えるとSEOに悪影響が出る
- 2026年はAIクローラー(GPTBot・ClaudeBot等)の制御とllms.txtとの併用が必須
robots.txtの設定は一度正しく行えば頻繁に変更するものではありませんが、サイトの構造変更やAIクローラーの登場など、環境が変わるタイミングで見直しが必要です。
まずは自サイトの https://あなたのドメイン/robots.txt にアクセスして、現在の設定内容を確認するところから始めましょう。構文に不安がある場合は、inSite robots.txtテスターで無料チェックできます。
\ テクニカルSEOの管理を自動化 /