noindexとは、特定のページをGoogle検索の結果に表示させないようにするためのタグです。
「noindexってどこに書くの?」「nofollowとは何が違うの?」「設定したのに効かないのはなぜ?」といった疑問を持つ方は多いでしょう。
noindexは正しく使えばサイト全体のSEO評価を守る強力なツールですが、設定を間違えると重要なページが検索結果から消えてしまうリスクもあります。
本記事では、noindexの仕組みからmetaタグでの書き方、設定すべきページの判断基準、確認方法、効かないときのトラブルシューティングまで、コード例付きで解説します。
\ インデックス状態を自動で監視 /
noindexとは?検索結果から除外するための仕組み
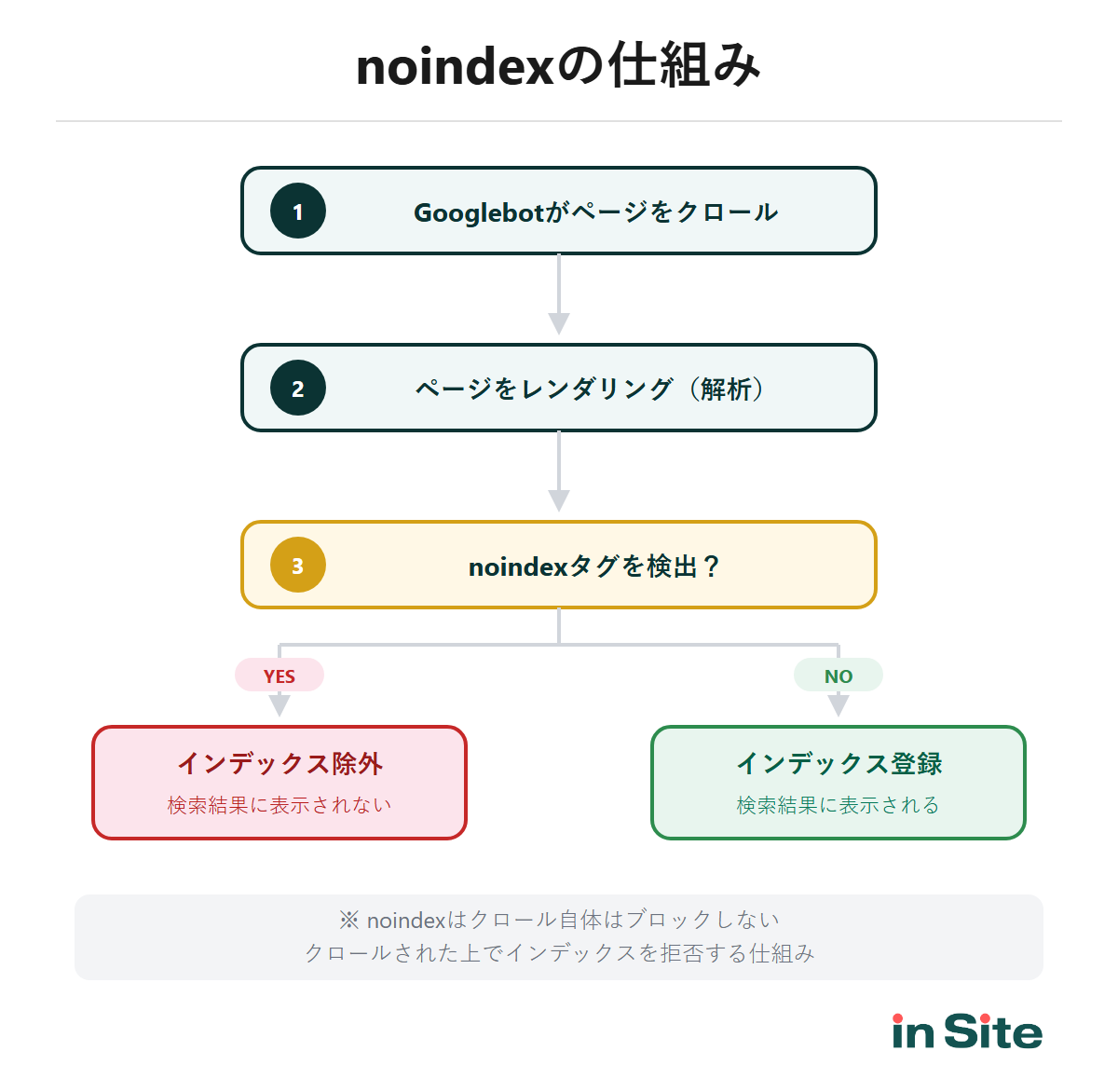
noindexは、Googlebotに「このページをインデックスに登録しないでください」と伝えるための指示です。
noindexを設定したページは、Googlebotにクロール(巡回)はされますが、検索結果には表示されなくなります。
Google検索セントラルでは、次のように説明されています。
ページのインデックス登録を防ぐ最も効果的な方法は、noindex robots meta タグまたは noindex HTTP レスポンス ヘッダーを使用することです。
nofollowとの違い
noindexとnofollowは名前が似ていますが、役割がまったく異なります。
| 項目 | noindex | nofollow |
|---|---|---|
| 役割 | ページのインデックスを制御 | リンクの評価受け渡しを制御 |
| 効果 | 検索結果に表示されなくなる | リンク先へPageRankが渡らなくなる |
| クロール | クロールされる | クロールされる場合がある |
この2つは併用することも可能です。noindex, nofollow と記述すると、「このページをインデックスしない」かつ「このページ上のリンクの評価を渡さない」という意味になります。
robots.txtとの違い
robots.txtとnoindexは、どちらも検索エンジンの動作を制御する仕組みですが、アプローチが異なります。
| 項目 | noindex | robots.txt |
|---|---|---|
| 制御対象 | インデックス登録 | クロール(巡回)自体 |
| クロール | 許可する | ブロックする |
| 設定場所 | 各ページのHTMLまたはHTTPヘッダー | サイトルートのrobots.txtファイル |
- robots.txtでクロールをブロックしているページにnoindexを設定しても、Googlebotがそのページを読み取れないためnoindexが機能しない
- noindexを使いたいページは、robots.txtのDisallowから除外しておく必要がある
canonicalとの使い分け
canonicalタグとnoindexは混同されやすいですが、用途が異なります。
| 状況 | 使うべき手段 | 理由 |
|---|---|---|
| 重複ページの評価を1つに集約したい | canonical | リンク評価を正規URLに集約できる |
| ページを完全に検索結果から除外したい | noindex | 確実にインデックスから外せる |
| 古いURLから新しいURLに恒久的に移動 | 301リダイレクト | ユーザーも検索エンジンも転送される |
重複コンテンツの対応では、まずcanonicalを検討しましょう。noindexはcanonicalでは対応できないケースや、そもそもインデックスさせる価値がないページに使います。
関連記事 canonicalタグとは?書き方・設定が必要なケース・確認方法をわかりやすく解説 →noindexを設定すべきページの判断基準
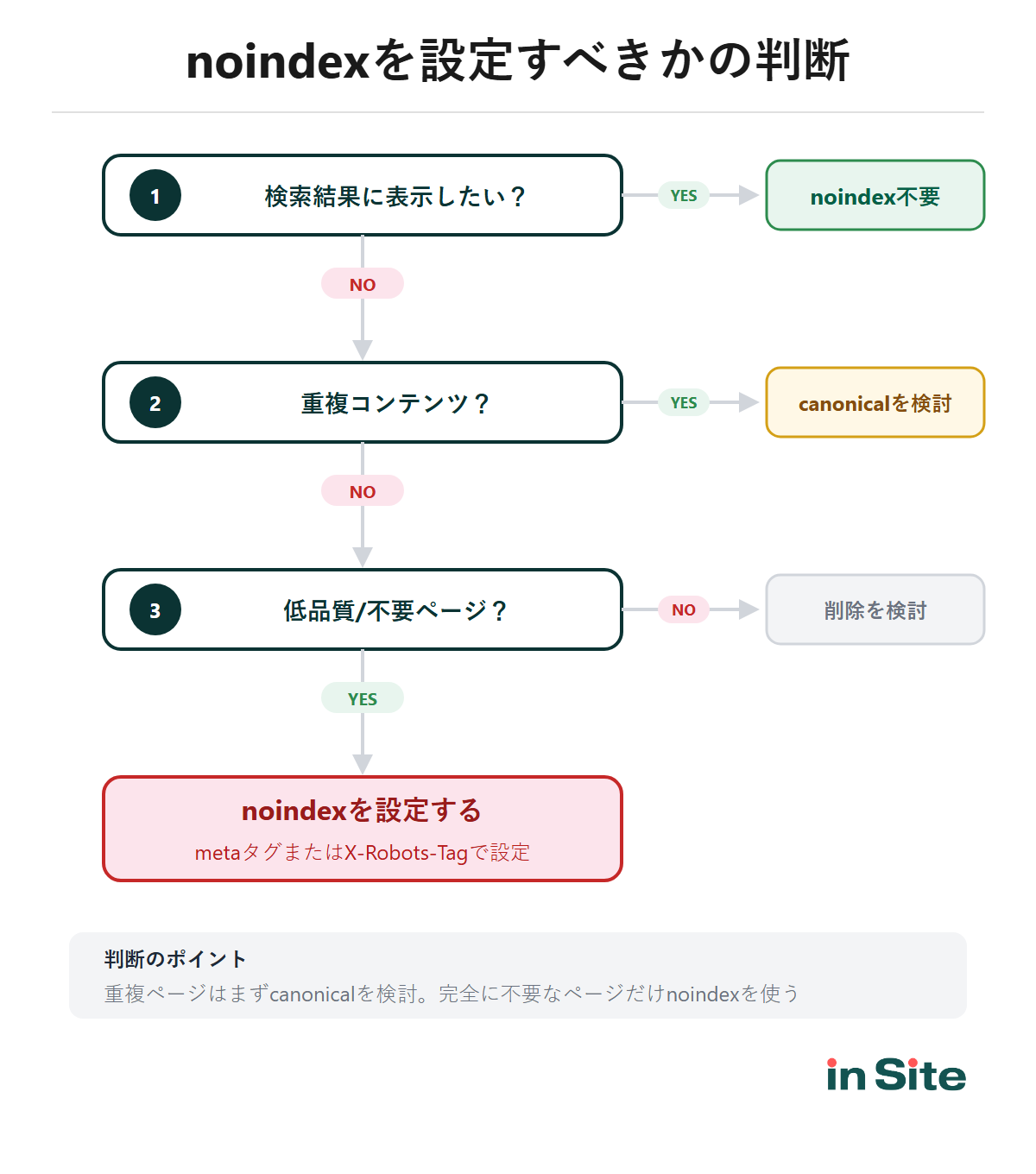
「このページにnoindexは必要?」という判断は、シンプルなフローで考えられます。
noindexを設定すべきページ
以下のようなページは、noindexを設定してインデックスから除外するのが適切です。
- 低品質ページ ─ 検索結果が0件のページ、コンテンツが薄いページ
- 重複コンテンツ ─ canonicalで対応できない場合(例えばパラメータ付きURLが大量にある場合)
- 管理画面・ログインページ ─ 一般ユーザーに見せる必要がないページ
- テスト環境・ステージング ─ 本番以外の環境が検索結果に表示されるのを防ぐ
- サンクスページ・フォーム完了ページ ─ フォーム送信後にしか到達しないページ
- HTMLサイトマップ ─ 大規模サイトでクロールバジェットを節約したい場合
noindexを設定すべきでないページ
- 検索流入を狙うページ ─ 当然ですが、noindexを設定すると検索結果から完全に消えます
- canonicalで対応可能な重複ページ ─ noindexだとリンク評価も失われるため、canonicalのほうが適切
誤って重要なページにnoindexを設定してしまうと、そのページが検索結果から消え、流入がゼロになります。設定変更の際は必ず対象URLを確認してから実行しましょう。
noindexの書き方と設定方法
noindexの設定方法は大きく3つあります。「noindexをどこに書くか」で迷ったら、まずはmetaタグでの設定を試してみてください。
metaタグで設定する(HTMLのhead内)
最も一般的な方法です。HTMLの<head>タグ内に以下のmetaタグを追加します。
<meta name="robots" content="noindex">
nofollowも同時に設定したい場合は、カンマ区切りで記述します。
<meta name="robots" content="noindex, nofollow">
- 必ず
<head>タグの中に記述すること。<body>内に書いても無効 - 他のmetaタグ(descriptionやviewportなど)と同じ場所に配置する
X-Robots-Tag(HTTPレスポンスヘッダー)で設定する
PDFや画像ファイルなど、HTMLではないファイルにnoindexを設定したい場合は、HTTPレスポンスヘッダーのX-Robots-Tagを使います。
Apacheの場合、.htaccessに以下を追加します。
<Files "secret-document.pdf">
Header set X-Robots-Tag "noindex"
</Files>
特定のディレクトリ全体に設定する場合は以下のように記述できます。
<Directory "/var/www/html/private/">
Header set X-Robots-Tag "noindex"
</Directory>
Nginxの場合は、該当のlocationブロックに追加します。
location /private/ {
add_header X-Robots-Tag "noindex";
}
WordPressでの設定方法
WordPressには、サイト全体をnoindexにする標準機能があります。「設定」→「表示設定」→「検索エンジンがサイトをインデックスしないようにする」にチェックを入れるだけです。
ただし、ページ単位でnoindexを設定したい場合は、SEOプラグインを使うのが一般的です。
- All in One SEO ─ 投稿編集画面の「AIOSEO設定」→「Advanced」→「Robots Setting」で「No Index」にチェック
- Yoast SEO ─ 投稿編集画面の「Yoast SEO」→「Advanced」→「Allow search engines to show this post in search results?」を「No」に設定
noindexが正しく設定されているか確認する方法
noindexは「設定したつもり」でも正しく反映されていないケースがあります。設定後は必ず確認しましょう。
ブラウザのソースコードで確認する
最も手軽な方法です。
<meta name="robots" content="noindex"> が <head> タグ内に存在すれば、正しく設定されています。
Google Search Consoleで確認する
サーチコンソールのURL検査ツールを使えば、Googleがそのページをどう認識しているかを確認できます。
URL検査の結果画面で「インデックス登録を許可?」が「いいえ: ‘noindex’ がrobots metaタグで検出されました」と表示されていれば、noindexが正しくGoogleに認識されています。
また、「ページのインデックス登録」レポートでは、noindexが設定されたページの一覧を「noindexタグによって除外されました」というステータスで確認できます。
関連記事 「noindexタグによって除外されました」とは?対処が必要なケースと解除方法 →inSiteの無料noindexチェッカーで確認する
URLを入力するだけで、そのページにnoindexが設定されているかを即座にチェックできる無料ツールを公開しています。
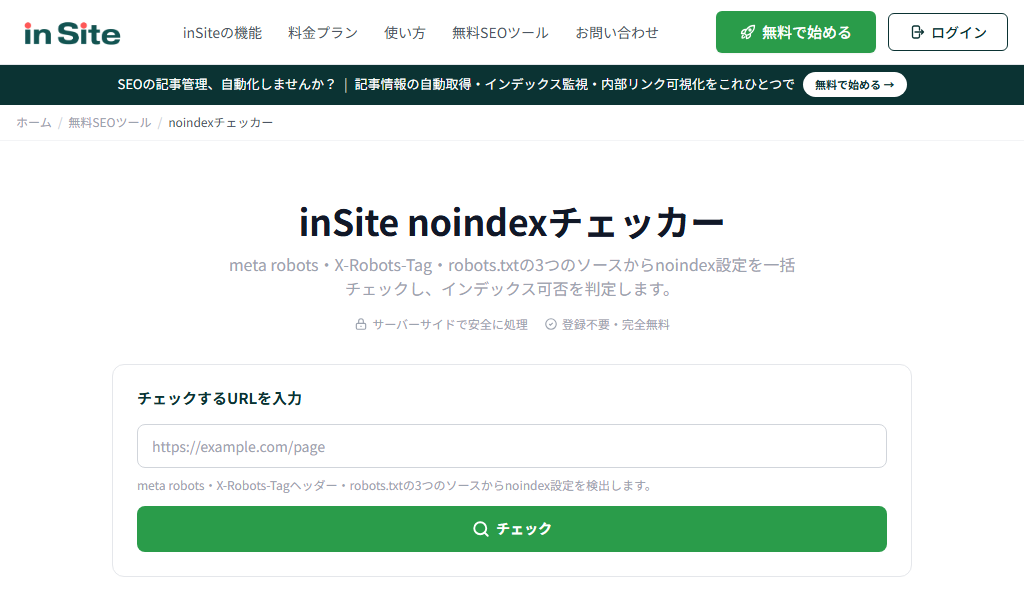
- meta robots、X-Robots-Tagヘッダー、robots.txtの3つのソースからnoindex設定を検出
- 自分のサイトだけでなく競合サイトの設定状況もチェック可能
- 登録不要、完全無料で利用できる
inSiteでnoindex状態を一括確認する
サーチコンソールのURL検査ツールでは、1ページずつURLを入力して確認する必要があります。ページ数が多いサイトでは現実的ではありません。
サイト管理ツールinSite(インサイト)なら、全ページのインデックス状態を自動でチェックし、noindexが設定されているページを一覧で確認できます。
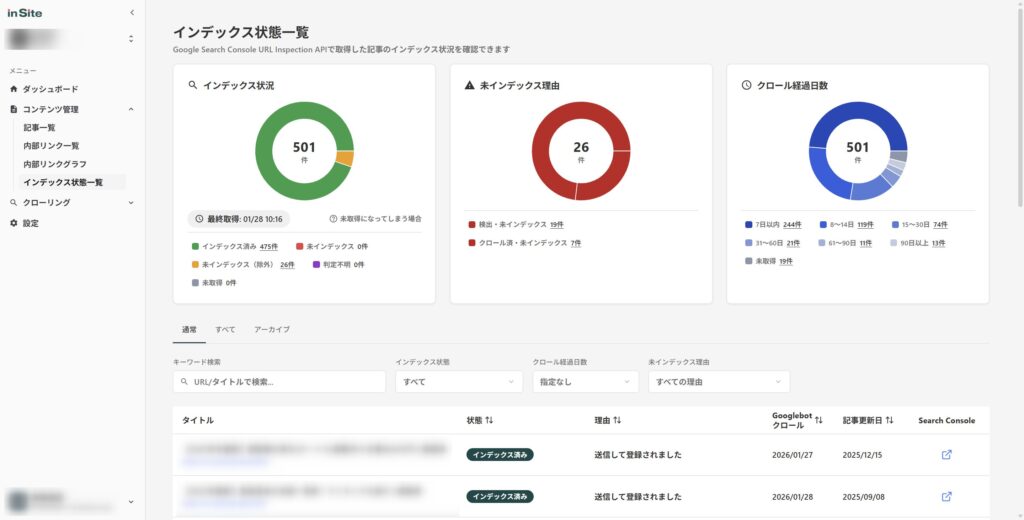
意図せずnoindexが設定されているページを発見した場合は、すぐに設定を解除してインデックス登録をリクエストしましょう。
noindexが効かない原因と対処法
「noindexを設定したのに、まだ検索結果に表示されている」という場合、いくつかの原因が考えられます。
robots.txtでクロールをブロックしている
最も多い原因です。robots.txtでクロールをブロックしているページにnoindexを設定しても、Googlebotがそのページにアクセスできないため、noindexタグを読み取れません。
noindexを機能させるには、Googlebotがそのページをクロールできる状態でなければなりません。
対処法は、robots.txtからそのページのDisallowルールを削除すること。noindexでインデックスを防ぎつつ、クロール自体は許可する形にしましょう。
関連記事 「robots.txt によりブロックされました」が発生する原因と対処法 →metaタグの記述場所が間違っている
noindexのmetaタグは、HTMLの<head>タグ内に配置する必要があります。<body>内に記述しても、Googlebotはそれをnoindex指示として認識しません。
ソースコードを確認して、metaタグが<head>と</head>の間にあるかチェックしてください。
キャッシュが残っている(反映に時間がかかる)
noindexを設定してもすぐには検索結果から消えません。Googlebotが次にそのページをクロールし、noindexを検出するまでには時間がかかります。
早く反映させたい場合は、サーチコンソールのURL検査ツールから「インデックス登録をリクエスト」を実行しましょう。それでも数日〜数週間かかることがあるため、焦らず待つことも大切です。
JavaScriptで動的に挿入している
JavaScriptでnoindexタグを動的に挿入するケースでは、Googlebotがレンダリングのタイミングによってnoindexを見逃す場合があります。
確実にnoindexを適用したい場合は、HTMLに直接metaタグを記述するか、X-Robots-Tag(HTTPレスポンスヘッダー)を使いましょう。HTTPレスポンスヘッダーはサーバー側で付与されるため、JavaScriptのレンダリングに依存しません。
よくある質問
まとめ
noindexの仕組みと設定方法、確認方法を解説しました。
- noindexは検索結果に表示させたくないページに設定するタグ
- metaタグまたはX-Robots-Tag(HTTPヘッダー)で設定できる
- robots.txtとの違いはクロールを許可するかどうか
- noindexが効かない主な原因はrobots.txtによるクロールブロック
- GSCの「noindexタグによって除外されました」で設定状況を確認できる
まずはサーチコンソールの「ページのインデックス登録」レポートで、意図しないnoindex設定がないか確認してみてください。低品質ページやテスト環境にはnoindexを適切に設定し、サイト全体のSEO評価を守りましょう。
\ noindex状態を自動で監視 /
inSite(インサイト)
全ページのインデックス状態・noindex設定を自動でチェック。意図しないnoindexの検出や、インデックスから外れたページの把握がかんたんに行えます。
無料で試してみる ↗