クロールバジェットとは、Googleがそのサイトに割り当てるクロール量のこと
クロールバジェットとは、Googleがそのサイトに割り当てるクロール量のことです。サイトの規模や状態に応じてGoogleが自動的に決めるもので、サイト側が設定で直接増減させることはできません。
Googleの公式ドキュメントでは、次のように定義されています。
クロール能力とクロールの必要性を併せて考えると、サイトに対するクロール バジェットとは、Google によるクロールが可能であり、かつクロールが必要な URL セットである、と定義できます。
Google 検索セントラル ─ クロール バジェットの管理(大規模サイト向け)
クロールバジェットを構成する2つの要素
クロールバジェットは、Googlebotが「どれくらいクロールできるか(クロール容量)」と、Googleが「どれくらいクロールする必要があるか(クロールの必要性)」の組み合わせで決まります。
どれだけサーバーに余裕があっても、Googleが確認する必要が少ないと判断すれば、クロール量は増えません。逆に、確認すべきURLが多くても、サーバー応答が不安定であれば、Googlebotはクロールを抑える可能性があります。

クロール容量は、サーバーが安全に処理できるクロール量
クロール容量は、Googlebotがサーバーに負荷をかけすぎないために自動調整される、同時接続数や取得ペースの上限です。
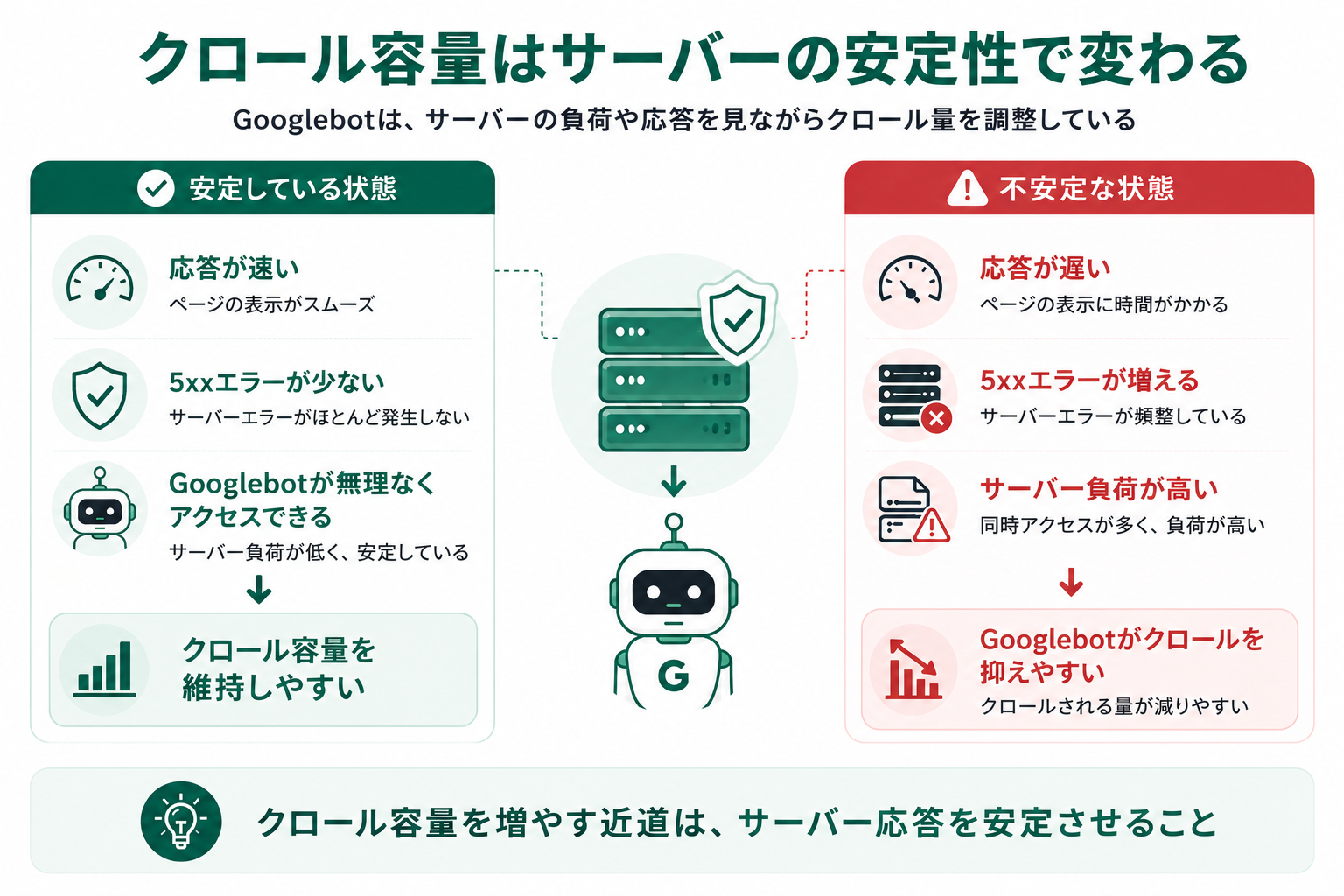
Googlebotはサーバーの応答速度・エラー率を継続的に観察しており、応答が安定していればクロールを増やし、遅延や5xxエラーが増えると自動的にクロールを絞ります。サーバーが遅い・不安定なサイトでは、クロール容量がじわじわ下がっていくと理解してください。
Search Consoleでクロール頻度の上限を上げる手動設定は提供されていません。容量を引き上げる主な手段は、サーバー応答時間(TTFB)の改善・5xxエラーの削減・キャッシュやCDNの活用など、サイト全体のパフォーマンス安定化です。
クロールの必要性は、GoogleがそのURLを再確認したい度合い
クロールの必要性は、Googleが「このURLは再確認しておきたい」と判断する度合いです。クロール容量に余裕があっても、再確認する理由のないURLは積極的にクロールされません。
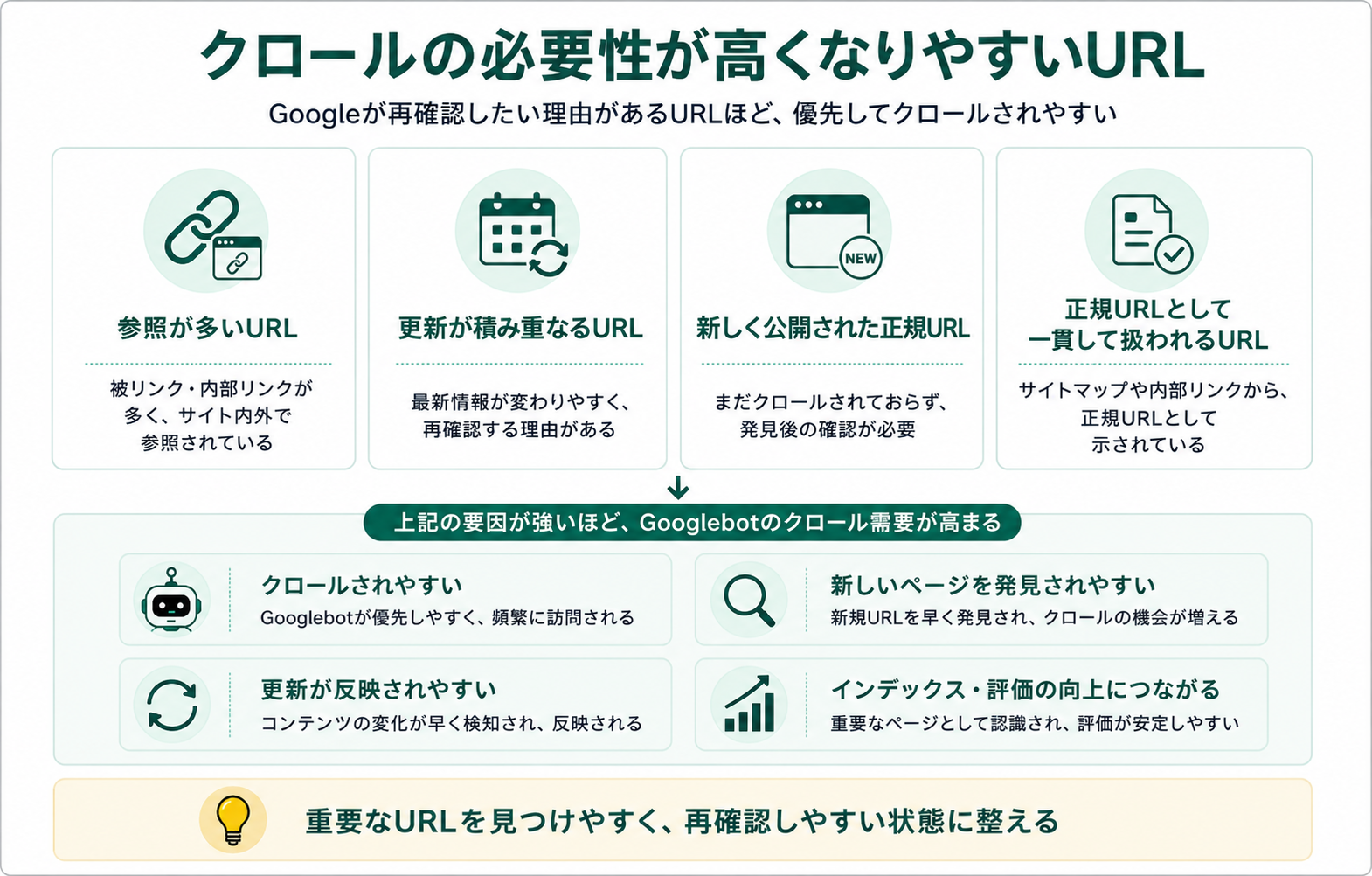
クロールの必要性が高くなりやすいURL
- 被リンク・内部リンクが多く、サイト内外で参照されているURL
- 更新が積み重なっていて、最新情報が変わるURL
- 新しく公開され、まだクロールされていない正規URL
- サイトマップや内部リンクから一貫して正規URLとして扱われているURL
逆に、長期間更新されない・どこからも参照されない・他のURLと内容が重複しているURLは、必要性が下がりやすい傾向があります。クロールの必要性は、内部リンク・サイトマップ・canonicalによる正規URLの指定など、サイト側のシグナル設計にも大きく影響されます。
クロールバジェットとクローラビリティの違い
クロールバジェットとクローラビリティは、クローラビリティが「Googlebotがページを発見してクロールできる状態か」の話、クロールバジェットが「限られたクロールをどのURLに使ってもらうか」の話と、扱う問題が違います。

クローラビリティでは、内部リンク・サイトマップ・robots.txt・JavaScriptレンダリング・URL構造などが論点になります。
クロールバジェットでは、サーバー応答・サイト全体の品質シグナル・URLの量と質が論点になります。
順序として、まず重要ページにGooglebotがたどり着ける状態(=クローラビリティ)を作ったうえで、不要URLを減らしてクロールバジェットを整える、という流れになります。基本的なクロールの流れはクローラーの仕組みで押さえておくと、両者の違いを理解しやすくなります。
小規模サイトでは、クロールバジェットの優先度は高くない
小規模サイトでは、クロールバジェットを最適化する優先度は高くありません。「インデックスされない」「クロールが遅い」と感じるとき、原因の多くはクロールバジェット不足ではなく、ページ品質・重複・canonical・内部リンク・インデックスさせる価値のいずれかにあります。
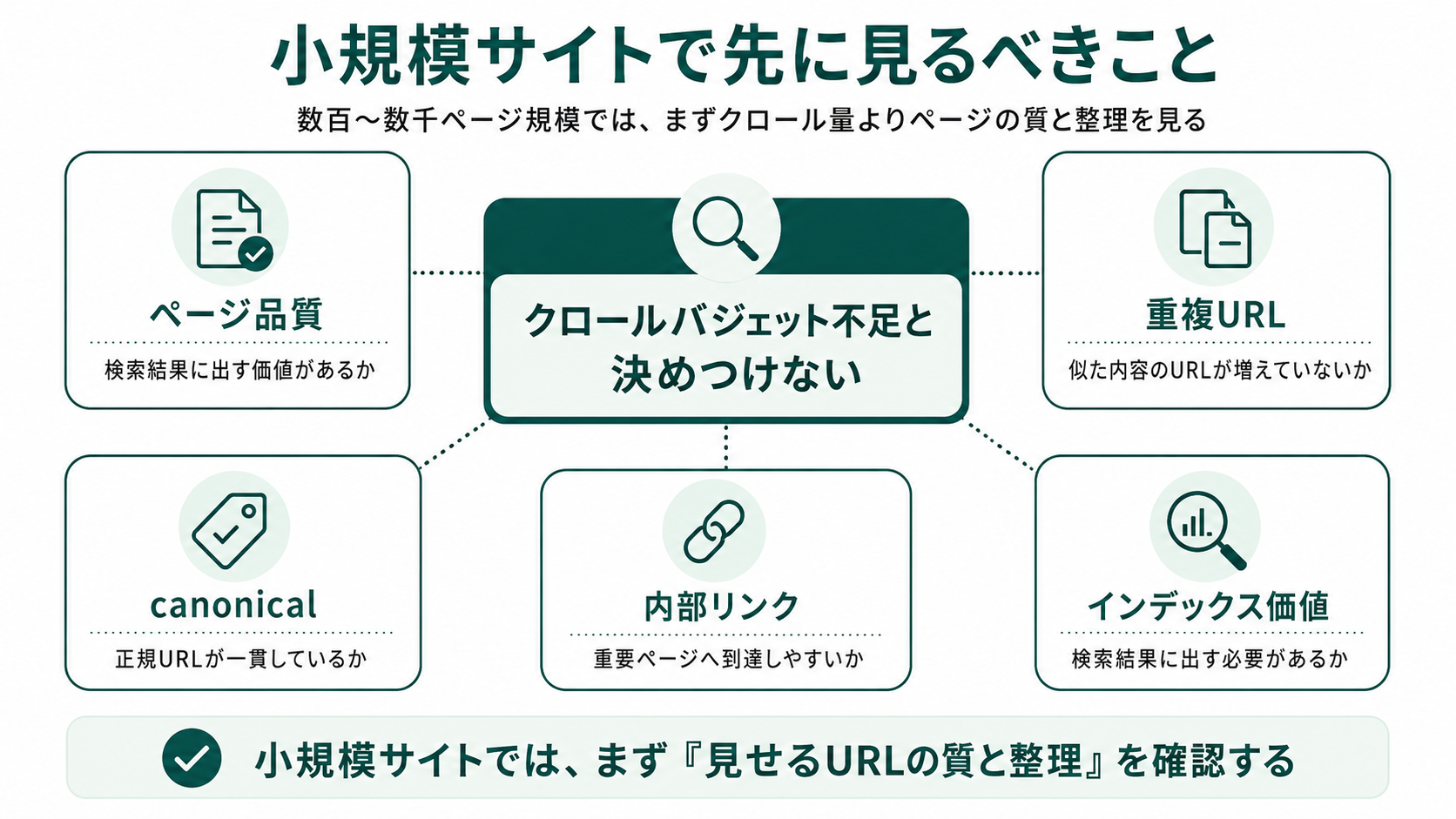
Google検索セントラルも、小規模サイトのオーナー向けに次のように明記しています。
URL が数千に満たない小規模なサイトでは、クロール バジェットについて心配する必要はほぼありません。
Google 検索セントラル ─ クロール バジェットの管理(大規模サイト向け)
数千ページ以下のコーポレートサイト・メディア・ブログでは、「クロールバジェット不足」と決めつけず、先に1記事あたりの品質・重複URLの整理・内部リンクの設計・インデックスさせる価値を点検しましょう。これらを整えればクロールの必要性も自然に高まります。
大規模サイトでは、不要URLの増加がクロールバジェットに影響しやすい
大規模サイトでは、ページ数の絶対値よりも、絞り込みやパラメータで指数的に増える不要URLが、重要URLの発見・再訪を遅らせる主な原因になります。EC・求人・不動産・UGCサイトなど、絞り込み条件・並び替え・検索結果ページ・カレンダー・セッションID付きURLが増えやすい構造のサイトでは、Googlebotが認識するURL候補が本来のページ数の数倍〜数十倍に膨らむことも珍しくありません。
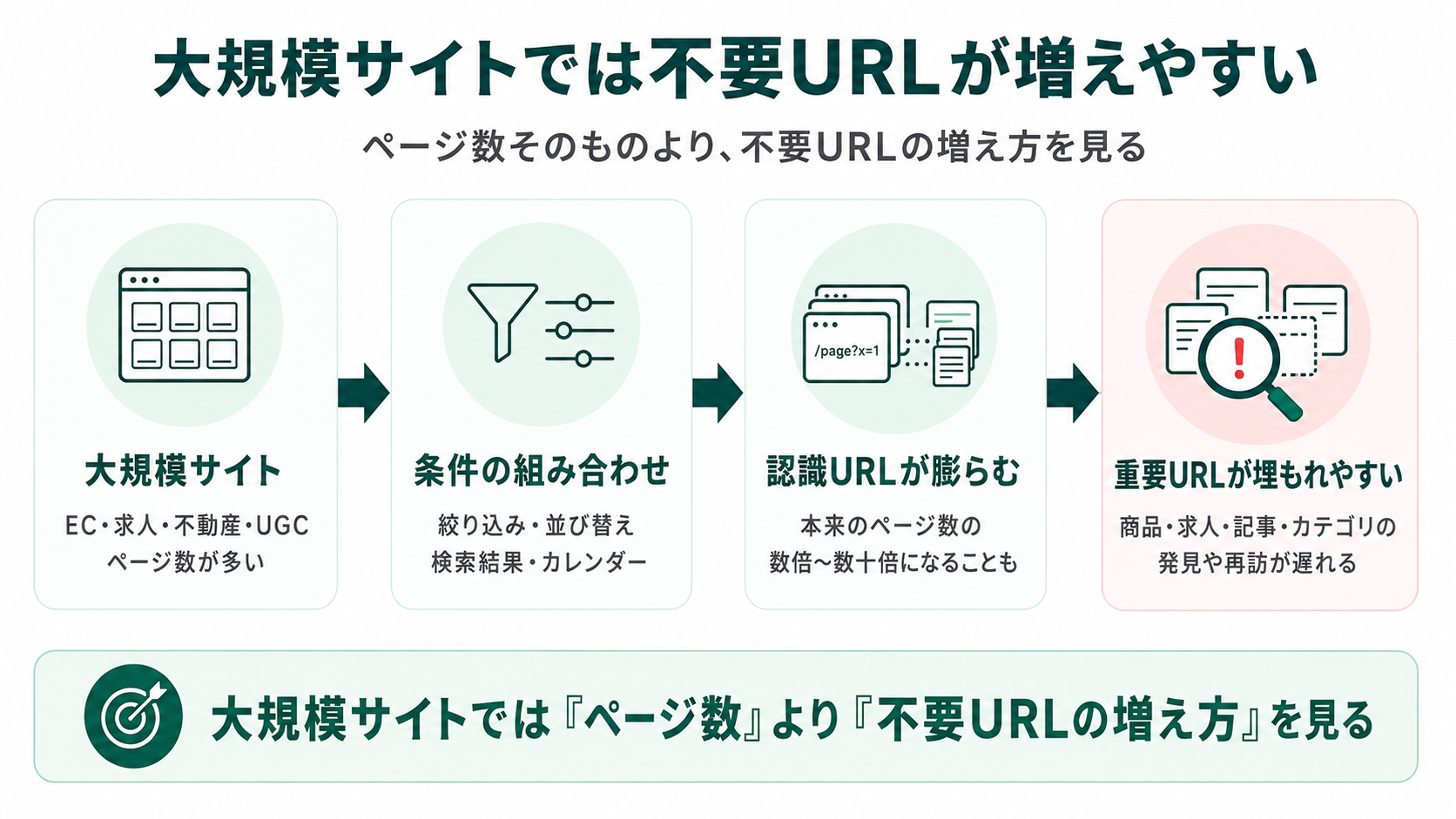
不要URLが増えるほど、本当に見せたい商品ページ・求人ページ・記事ページ・カテゴリページの発見や再訪が遅れやすくなります。大規模サイトのクロールバジェット対策の本質は、容量を増やすことでも必要性を煽ることでもなく、Googleに認識させる必要のないURLを減らすことにあります。
ここから先は、まず「どんなURLが浪費しやすいか」を整理したうえで、Googlebotから優先的にクロールされやすいページの特徴・不要URLの整理方法・クロール状況の確認方法、の順で解説します。
クロールバジェットを浪費しやすいURL
クロールバジェットを浪費しやすいURLには、構造的に増えやすいパターンがあります。サイト全体のURLを点検する際の出発点として、以下のタイプを把握しておきましょう。
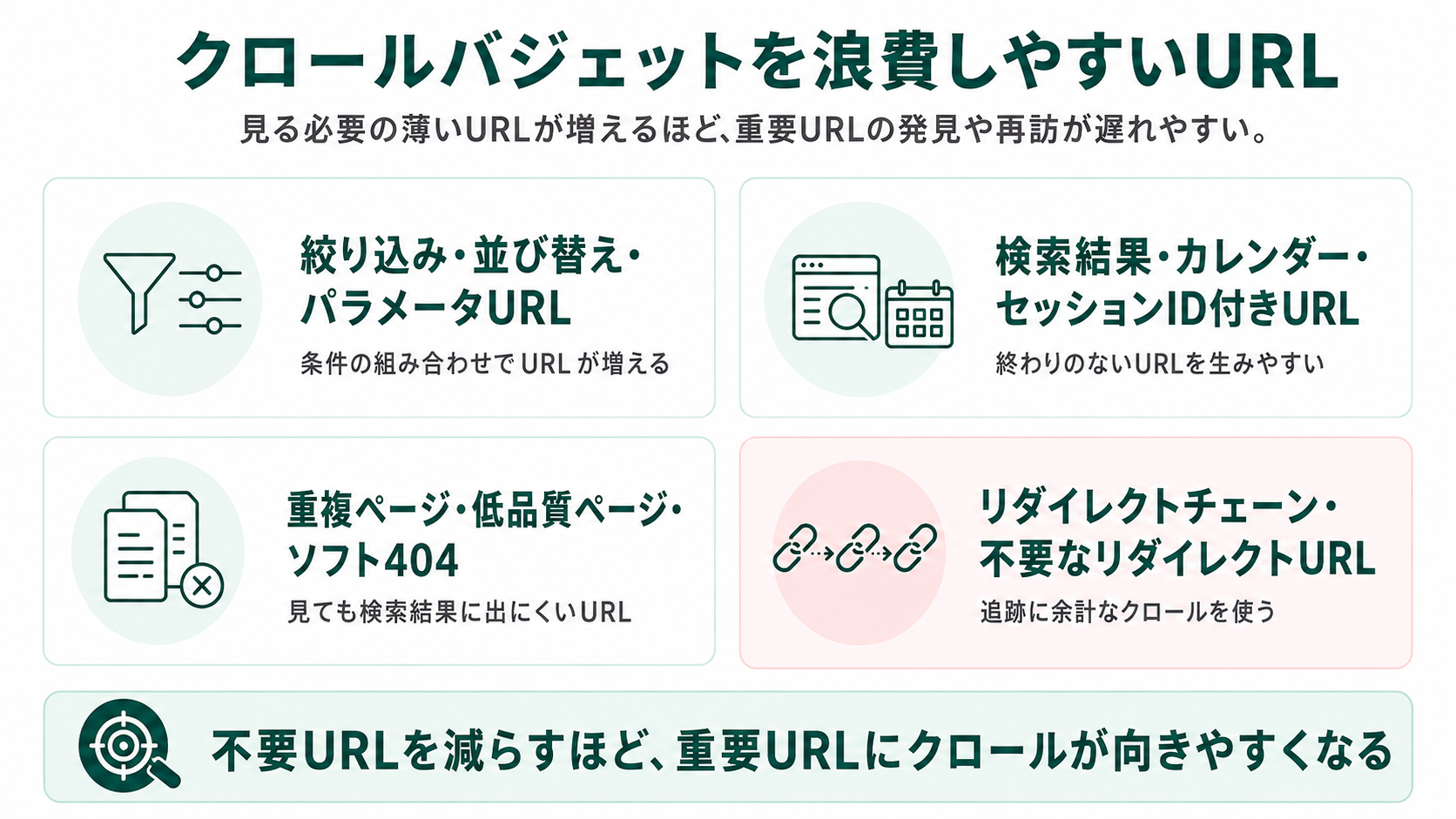
絞り込み・並び替え・パラメータURL
ファセットナビゲーション(絞り込み機能)は、条件の組み合わせの数だけURLを生み出す構造です。ECサイトの絞り込み機能・求人サイトの条件指定・不動産サイトのエリア×物件種別など、複数の条件をユーザーに選ばせる仕組みがすべてこのパターンに該当します。
?color=red ?color=red&size=m ?color=red&size=m&sort=price のようにパラメータが組み合わさるたびに、URLは新しいものとして認識されます。商品数100点のサイトでも、絞り込み条件次第でGoogleが認識するURLは数万〜数十万に膨らむ可能性があります。
求人・不動産・データベース型サイトでは、エリア × 業種 × 給与 × 雇用形態 × ソート順のように、組み合わせ次第で結果0件や極端に薄いページが量産されやすい構造でもあります。これらの大半は検索結果に出す価値が低く、Googlebotに見せる必要はありません。
検索結果ページ・カレンダー・セッションID付きURL
クロールバジェットの観点で特に問題になりやすいのが、終わりのないURL生成です。
無限にURLが増えやすいパターン
- カレンダーの「前月」「翌月」リンクが、何百年先までリンクをたどれる状態になっている
- サイト内検索結果ページが、任意のクエリでインデックス対象になっている
- セッションIDやトラッキングパラメータが、リンクするたびに新しい値で付与される
- ページネーションが、存在しないページ番号でも200を返してしまう
これらは1つのリンクから理論上無限にURLが派生するため、放置するとGoogleの認識URLが急増する原因になります。
重複ページ・低品質ページ・ソフト404
重複ページ・低品質ページ・ソフト404も、Googlebotのクロール時間を奪いやすいパターンです。サイト内に同じ内容を持つ複数のURLがある状態(重複ページ)、本文がほぼ無い・独自性のないページ(低品質ページ)、削除されているのに200を返してしまうページ(ソフト404)が代表例です。
これらのURLは、Googleがインデックス対象にする価値を判断するためにクロールしますが、結果として検索結果に出ないことが多く、クロールリソースが効果を生まない状態になります。重複URLは代表URLに寄せる、低品質ページは整理または削除する、ソフト404は適切なステータスコード(404/410)に修正する、の対応が基本です。
リダイレクトチェーンや不要なリダイレクトURL
リダイレクトチェーンは、長いほどクロールが無駄になり、URL移転のシグナルも弱まります。A → B → C → D のようにリダイレクトが何段も続くと、Googlebotが途中で追跡を諦めやすく、段ごとにクロールも消費されます。
サイトリニューアル後に古いURLを残し続けている・複数回のURL変更で旧URLが層になっている、といったケースでは、A → 最終URL の直接リダイレクトに整理しておきましょう。
これらのURLが増えると、Googlebotが見る必要の薄いURLにクロールを使いやすくなり、重要URLの発見や再訪が遅れやすくなります。大規模サイト・URLが大量に増えるサイトほど、定期的な点検と整理が効いてきます。
Googlebotから優先的にクロールされやすいページ
Googlebotから優先的にクロールされやすいのは、サイト内外で多く参照されているページ・更新が積み重なっているページ・新しく公開された正規URL・内部リンクで一貫して示されているページです。
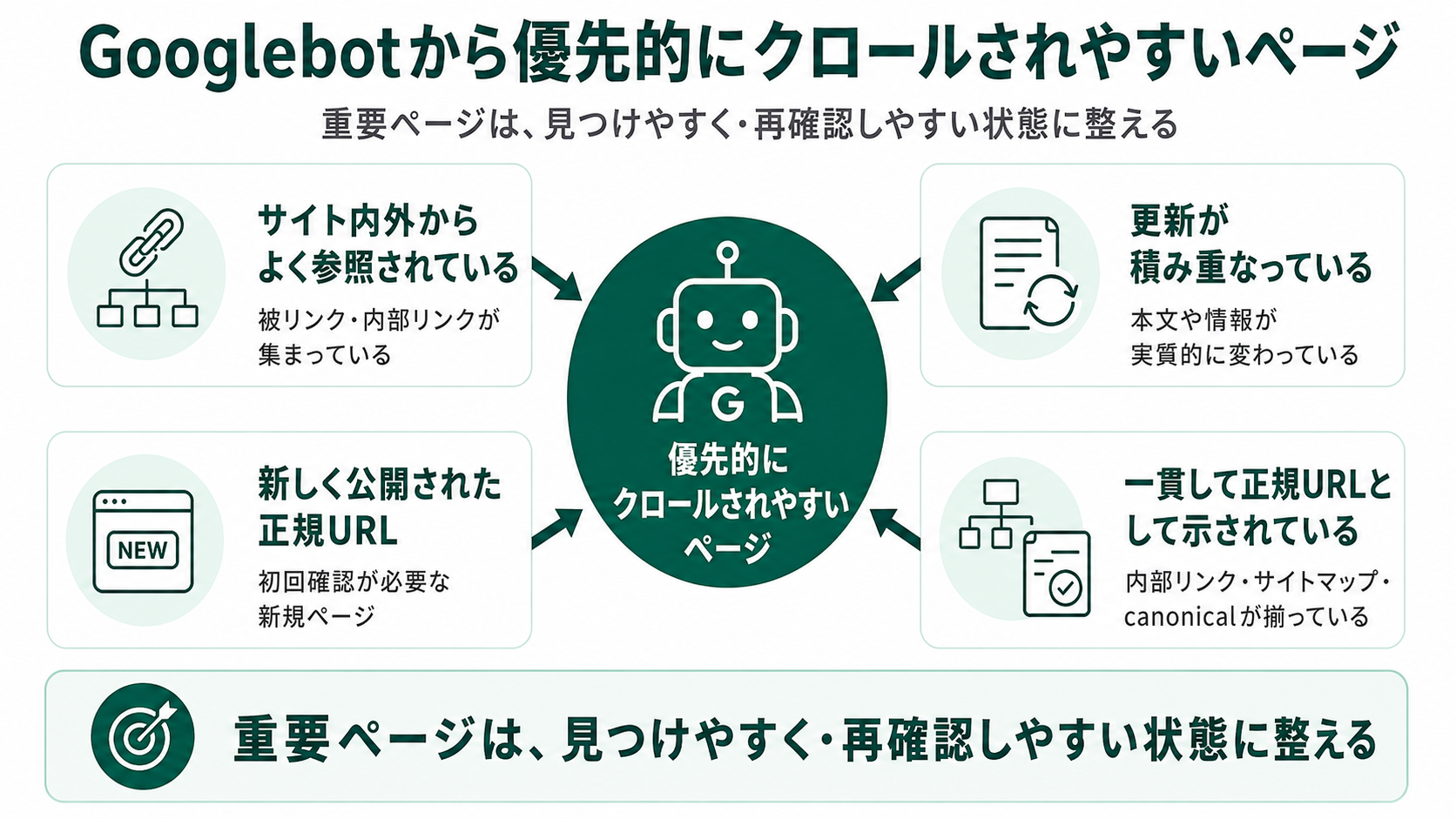
Google検索セントラルは、クロールの必要性を決める要素として「検出されたURL群、人気度、古さ」の3つを挙げています。
クロールの必要性を決定する重要な要素は次のとおりです。検出された URL 群、人気度、古さ。
Google 検索セントラル ─ クロール バジェットの管理(大規模サイト向け)
これらの要素から、Googlebotが優先的にクロールしやすいページの特徴を、サイト側から見える観点で整理します。
サイト内外からよく参照されているページ
被リンクや内部リンクが多く、サイト内外で参照されているページは、Googleにとって重要なURLとして認識されやすくなります。トップページ・カテゴリトップ・主要記事のように、サイトの動線が集中しているページがこれに当たります。
公式ドキュメントでも、「インターネット上で人気の高いURLほど、Googleのシステムで情報の新しさが保たれるよう頻繁にクロールされる傾向がある」と説明されています。
更新が積み重なっているページ
定期的に本文が更新されているページ・新しい情報が追加されているページは、再確認の必要性が高まり、クロール頻度が上がりやすい傾向があります。
ただし、更新日(lastmod)の数値だけを書き換えても、本文の中身が変わっていなければ Googlebot は徐々に信頼しなくなります。lastmodは「実質的な更新があったときに、それを伝えるための情報」として運用しましょう。
新しく公開された正規URL
公開直後の正規URLは、Googleにとって「初めて見るURL=確認が必要」な状態です。新規記事・新商品ページ・新カテゴリなどは、初回クロールに比較的早く回ってくる傾向があります。
新しいURLを発見してもらうには、サイト内の関連ページからリンクを設置する・XMLサイトマップに含める、といった経路を整えておくのが有効です。
内部リンクやサイトマップで一貫して示されているページ
内部リンク・XMLサイトマップ・canonical・パンくずリストなどが同じURLを「正規URL」として一貫して指していると、Googleの判断が安定し、そのURLにクロールが集中しやすくなります。
逆に、サイトマップにしか載っていないページ・どこからもリンクされていないページは、サイト内での重要度がGoogleに伝わりにくく、必要性が下がりやすい傾向です。重要ページは、本文・カテゴリ・関連リンクから自然に到達できる状態を維持しましょう。
不要URLを減らし、重要URLを見つけやすくする方法
クロールバジェット対策の中心は、技術設定の足し算ではなく、Googleに見せるURLの引き算です。下記の仕組みを、クロール節約への効果が大きい順に並べました。「とりあえずnoindex」「とりあえずrobots.txt」とせず、目的に合わせて使い分けましょう。

robots.txtでクロールさせないURLを制御する
robots.txtは、Googlebot自体にURLをクロールさせないことを指定するファイルです。クロール自体をブロックするため、不要URLの整理として最も直接的に効きます。ファセットナビゲーションのように無限に増えるURLパターンや、サイト内検索結果・カート・テスト環境などを一括で制御できます。
ただし、robots.txtは検索結果からURLを確実に消すための仕組みではありません。すでにインデックスされているページや、外部リンクから発見されるURLを検索結果から外したい場合は、noindex・404/410・認証制限など、目的に合った方法を選ぶ必要があります。
robots.txtでよくある誤解
- robots.txtでブロックしても、外部からリンクされていれば検索結果にURLだけ表示される場合がある
- noindexタグはクロールされて初めて読まれるため、robots.txtでブロックしているページにnoindexを書いても伝わらない
- サイト内検索結果やパラメータURLを大量にブロックする場合は、Disallowルールの記述ミスに特に注意する
詳細な書き方とハマりやすい落とし穴はrobots.txtによるクロール制御で解説しています。
canonicalで重複URLの代表を伝える
canonicalは、複数のURLで同じ内容を提供している場合に、代表となる正規URLを伝えるためのシグナルです。クロール制御ではなく、Googleの内部での重複統合に関わる仕組みで、EC・パラメータURL・印刷用ページなど、重複構造を持つサイトでクロール集約の効果が大きいのが特徴です。
canonicalで指定しても、Googleが必ず従うとは限らない点に注意してください。canonicalタグ・サイトマップ・内部リンクが同じURLを指していると、Googleの判断が安定します。canonicalの仕組みと優先順位はcanonicalによる正規URLの指定で、関連する重複コンテンツの整理もあわせて確認してください。
301/308で移転したURLを統合する
301/308リダイレクトは、URLが恒久的に別のURLに移ったことを伝えるためのHTTPステータスコードです。サイトリニューアルやURL構造の変更に使い、移転先にクロールとシグナルを統合できるのが効果のポイントです。
リダイレクトが何段も続くリダイレクトチェーンは、Googlebotが途中で追跡を諦める原因になりやすく、URL移転のシグナルが弱まります。可能な限り、A → 最終URL の直接リダイレクトに整理してください。
404/410で削除済みURLを伝える
404と410は、削除されたURLをGoogleに伝えるためのHTTPステータスコードです。404は「現時点で見つからない」、410は「永久に削除された」という意味で、410の方がGoogleがクロール対象から外すまでの時間が短い傾向があります。
404/410はSEOの失敗ではなく、削除済みURLをGoogleに正しく伝えるための正常なサインです。消したいだけのURLに無理やりリダイレクトを設定すると、関係のないページへの誘導になり、別の問題を生みます。実際には削除されているのに200を返してしまうソフト404は、Googleの判定が安定しない原因になるため避けましょう。サイトの不要URLを整理する場合は、削除でいいなら404/410、別ページに引き継ぐなら301/308を使い分けます。
XMLサイトマップで見てほしい正規URLを伝える
XMLサイトマップは、サイト内に存在する全URLの一覧ではなく、Googleに見てほしい正規URLを整理して伝えるためのリストです。直接的なクロール制御ではありませんが、Googleの認識URLの中で「重要URL」を強調することで、クロールが優先的に重要URLへ向かいやすくなる補助的な役割を担います。
サイトマップ上のシグナルがcanonicalや404/410と矛盾しないよう、noindexページ・リダイレクト元URL・404/410・別URLをcanonicalにしているURLは除外します。lastmodは更新アピールではなく、Googlebotに再確認する理由を伝えるための情報として使い、詳しい運用はXMLサイトマップに載せるURLで整理しています。
noindexで検索結果から除外する
noindexは、Googleがページをクロールしたうえで、検索結果に出さないことを指定するメタタグです。Googlebotがnoindexを確認するには、そのURLをクロールする必要があります。そのため、noindexは「クロールさせない指定」ではなく、「クロールされたあと、検索結果に残さない」ための指定です。
短期的なクロール節約にはなりませんが、検索結果に出す必要のないページをnoindexで整理しておくと、Googleに「このURLはインデックス対象ではない」と伝えられます。長期的にはサイト内で検索結果に出したいURLと、出したくないURLの区別が明確になり、URL整理の一部として機能します。
クロールさせたくないURLにはrobots.txt、削除済みURLには404/410、重複URLにはcanonicalや301を使うなど、目的に応じて使い分けましょう。詳しい使い分けはnoindexはインデックス制御で解説しています。
クロール状況は、複数のデータで確認する
クロールバジェットそのものを直接確認することはできませんが、Search Console・URL検査・サーバーログ・サイト管理ツールを組み合わせれば、クロール状況を複数の角度から把握できます。1つのレポートだけで判断せず、症状ごとに見るべき場所を切り替えてください。
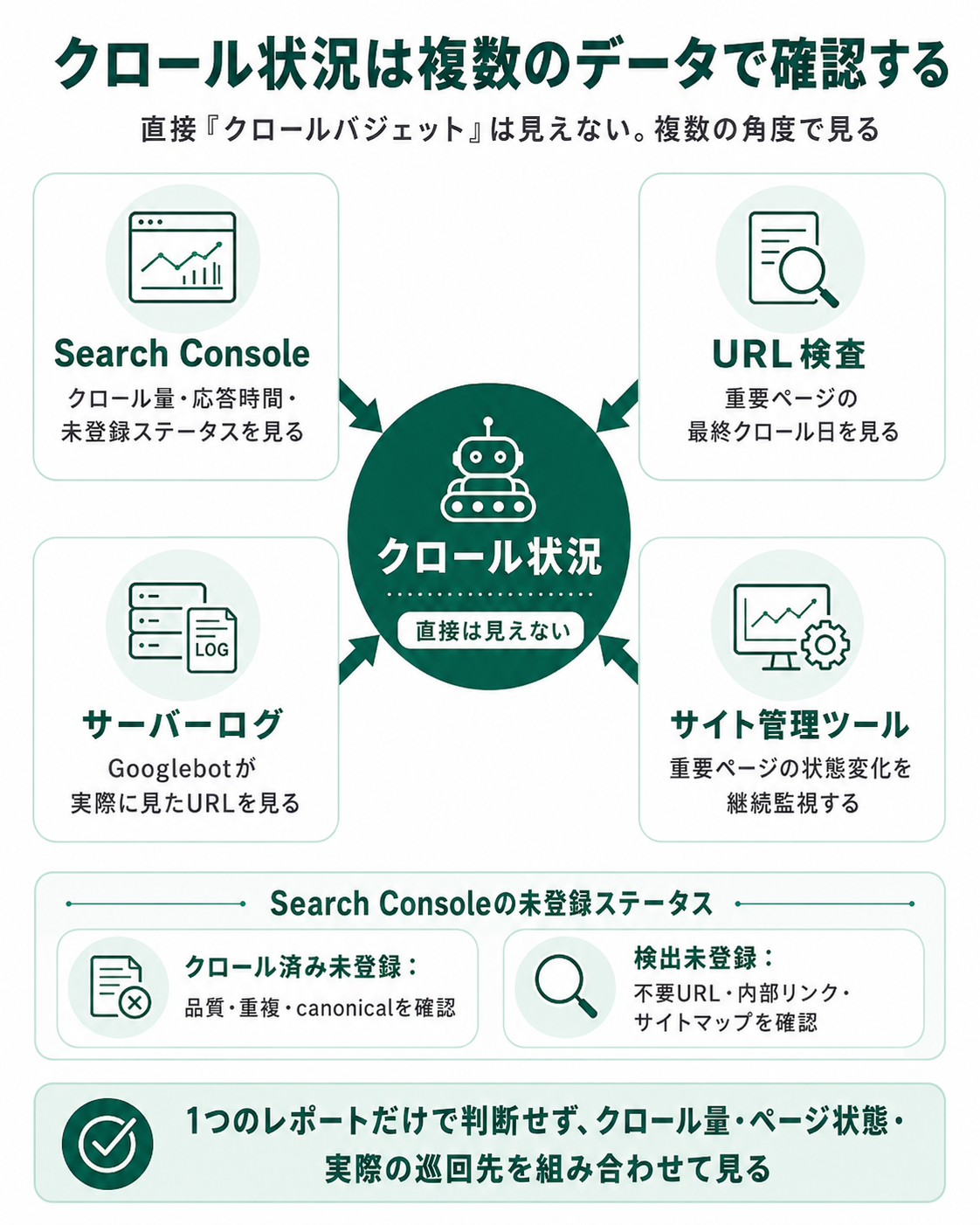
Search Consoleでクロール量と未登録ステータスを見る
Search Consoleの「設定」 → 「クロールの統計情報」では、Googlebotのクロール量とサーバー応答の概況を確認できます。
クロールの統計情報で見るべき指標
- クロールリクエストの合計数(直近のクロール量の推移と急減/急増)
- 平均応答時間(増加傾向はクロール容量低下のサイン)
- レスポンス別の内訳(404/5xxが急増していないか)
- ファイル形式別/Googlebot種類別(意図しないBotが多い・画像が大半など偏りの確認)
各指標の詳しい読み方や異常値の対処法はSearch Consoleのクロールの統計情報で整理しています。
あわせて、Search Consoleの「ページ」レポート(旧:インデックスカバレッジ)で未登録ステータスを確認します。
「クロール済み - インデックス未登録」は、GooglebotがすでにそのURLを見たうえでインデックスしていない状態です。クロール量よりも、ページ品質・既存ページとの重複・別URLをcanonicalにしていないか・noindexの有無・インデックスさせる価値を確認します。原因の切り分け方はクロール済み - インデックス未登録で、ステータス全体の意味はインデックスカバレッジの全18ステータスで詳しく解説しています。
「検出 - インデックス未登録」は、GoogleがURLを認識しているもののまだクロールしていない状態です。大規模サイトやURLが大量に増えるサイトでは、不要URLの増加・内部リンク・XMLサイトマップ・クロール優先度を確認します。
URL検査で重要ページの最終クロール日を見る
特定のページがいつクロールされたか確認したい場合は、URL検査ツールが手早く使えます。重要ページの最終クロール日時が古いまま放置されていないか、定期的に確認しましょう。
最終クロール日時が想定より古い場合は、内部リンク・サイトマップ・lastmod・本文の更新有無を見直してください。
サーバーログでGooglebotが実際に見たURLを見る
より詳細にクロール挙動を追いたい場合は、サーバーアクセスログからGooglebotのリクエストを抽出する方法があります。
ログ解析では、Googlebotが「実際に」どのURLにどれだけクロールを使っているかを確認できます。重要ページの再訪間隔・絞り込みURLへのアクセス比率・404/5xxの発生箇所など、Search Consoleでは見えない粒度で挙動を把握できる方法です。一定の規模を超える大規模サイトでは、ログ解析が現実的な選択肢になります。
サイト管理ツールで重要ページの状態変化を継続監視する
ページ数が多いサイトでは、URL検査ツールを1ページずつ実行するのは現実的ではありません。重要ページのクロール頻度低下・削除済みURLの残存・canonical不一致など、ページ単位の状態を継続的に確認したい場合は、サイト管理ツールでの自動監視が向いています。
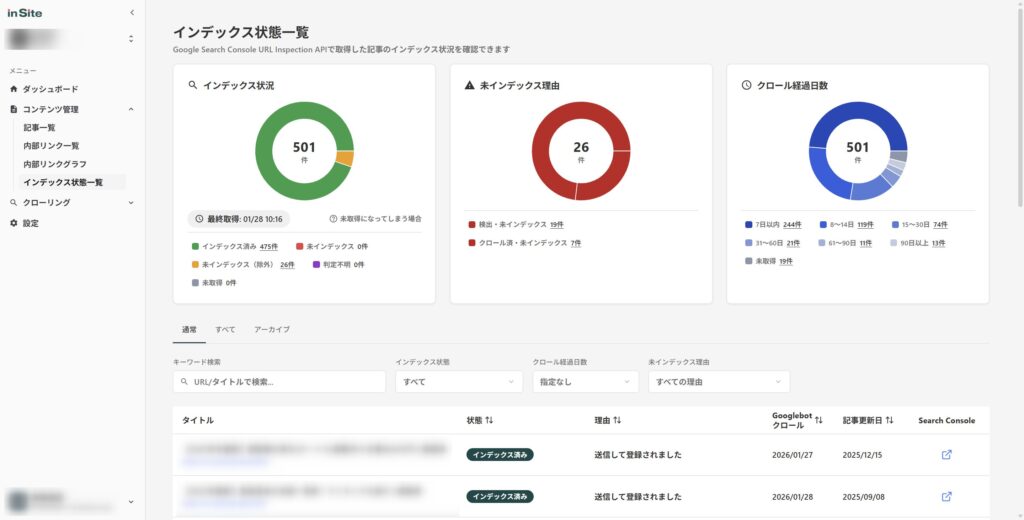
サイト管理ツールinSite(インサイト)は、Search Consoleと連携して全ページのクロール状態を自動取得し、ページ単位の状態を一覧で把握できる設計です。
inSiteでクロールバジェット運用に使える機能
- 最終クロール日の一覧(古いまま放置されているページを発見できる)
- インデックスステータスの一覧(登録済み・未登録の判定状況をまとめて確認)
- canonical不一致の検出(指定先と実際の正規URLのズレを検出)
- 内部リンク状況(リンク元URL・本数をページ単位で確認)
- 削除済みURLの残存検出(404/410が返るのにサイトマップ等に残っているケース)
URL検査ツールが1ページずつしか確認できないことを、APIとスプレッドシートで補う方法はインデックス状況の一括チェックで解説しています。ただし、ページ数が増えるほど専用ツールでの自動化が現実的です。
クロールバジェット運用で確認したい7つの観点
日々の運用で確認する項目を、サイト全体のクロールバジェット運用としてチェックリストにまとめました。
クロールバジェット運用チェックリスト
- サイトの規模・構造から、クロールバジェットを優先課題にすべきかを判断している
- 絞り込み・並び替え・パラメータURLが、Googleにそのまま見せ続けていないか確認している
- noindex・robots.txt・canonical・404/410・301/308を役割で使い分けている
- XMLサイトマップに、見てほしい正規URLだけを載せている
- サーバー応答時間とエラー率を継続的にモニタリングしている
- Search Consoleのクロールの統計情報・URL検査・ページレポートを定期的に確認している
- 重要ページのクロール頻度低下や削除済みURLの残存を、サイト管理ツールでも監視している
よくある質問
クロールバジェットの最適化方法は?
「不要なURLを減らし、重要URLを見つけやすくする」ことが本質です。具体的には、重複URLをcanonicalや301で代表URLに寄せる、クロールさせたくないURLをrobots.txtで制御する、削除済みURLは404/410を返す、サイトマップには見てほしい正規URLだけを載せる、サーバー応答速度を維持する、の5点が基本です。クロール上限を増やすこと自体は対策の本筋ではありません。
クロールバジェットは小規模サイトでも気にするべきですか?
数千ページ以下のサイトでは基本的に気にしなくてよい、というのがGoogle公式の説明です。インデックスされない・検索結果に反映されないと感じるときは、クロールバジェットではなく、ページ品質・重複・canonical・内部リンクの問題であるケースがほとんどです。先にこれらを点検しましょう。
noindexを設定すればクロールバジェットは節約できますか?
短期的なクロール節約にはなりません。noindexは、Googlebotがページをクロールしたあとで検索結果から外す指定だからです。ただし、検索結果に出す必要のないページをnoindexで整理すること自体は重要です。noindexはクロール制御ではなく、インデックス対象を整理するための指定として使いましょう。
robots.txtでブロックすれば、重要ページのクロールは増えますか?
直接増えるとは限りません。robots.txtで不要URLをブロックしても、その分のクロールが必ず重要ページに回るわけではありません。ただし、無限に増えるURLや明らかに不要なURLを長期的にクロール対象から外すことで、Googlebotが見るべきURLを整理しやすくなります。
クロール頻度が上がると検索順位も上がりますか?
上がりません。クロール頻度はランキング要因ではなく、Googleがコンテンツを再確認する頻度の指標です。逆に、クロール頻度が低くても上位表示されているURLは多数あります。クロール頻度を直接上げる施策ではなく、コンテンツ品質と内部リンクを整えた結果として、必要なURLが適切な頻度で再訪される状態を目指してください。
「クロール済み - インデックス未登録」はクロールバジェットの問題ですか?
多くの場合、クロールバジェットではなく品質・重複・canonicalの問題です。クロール済みである時点でクロール容量・必要性は割り当てられており、インデックスを見送られている理由は別にあります。本文の薄さ・既存ページとの重複・別URLをcanonicalにしていないか・内部リンクから到達できるか、を順番に点検してください。
クロールバジェットとクローラビリティは何が違いますか?
クローラビリティは「Googlebotがページを発見し、問題なくクロールできる状態か」、クロールバジェットは「限られたクロールをどのURLに使ってもらうか」の話です。クローラビリティが整っていない状態でクロールバジェットを論じても効果は出ません。順序として、まず内部リンク・サイトマップ・JS描画などのクローラビリティを整えてから、不要URLの整理に進むのが基本です。
クロールバジェットを含むサイト全体のSEOチェックは「SEOチェックリスト」で、Googlebotの基本挙動はクローラーの仕組みで確認できます。
クロールバジェット最適化は、不要なURLを整理し、重要URLを見つけやすくすることから始まる
クロールバジェット最適化の出発点は、新しい施策を足すことではなく、Googleに見せる必要のないURLを減らすことです。
クロールバジェット対策は、サイトのURL設計の延長線上にあるテーマです。日々のリリース・記事追加・カテゴリ整理のたびに、「このURLをGoogleに見せる必要があるか」を判断する習慣を持つことが、長期的なサイト運用に効いてきます。
サイトマップ・canonical・内部リンクと合わせて整える方法は、XMLサイトマップに載せるURL・canonicalによる正規URLの指定・robots.txtによるクロール制御を行き来しながら確認してください。
この記事のポイント
- クロールバジェットとは、Googleがそのサイトに割り当てるクロール量のこと
- クロール量は「クロール容量(処理できる量)」と「クロールの必要性(再確認したい度合い)」の組み合わせで決まる
- 数千ページ以下のサイトでは優先度は高くなく、品質・重複・内部リンクを先に見る
- 大規模サイトでは、不要URLの増加が重要URLの発見・再訪を遅らせる
- 浪費しやすいURLは、絞り込み・検索結果・重複・リダイレクトチェーンなどに分類できる
- 不要URLの整理は、robots.txt・canonical・301/308・404/410・XMLサイトマップ・noindexを目的別に使い分ける
- クロール状況はSearch Console・URL検査・サーバーログ・サイト管理ツールで複数の角度から確認する