クローラーとは、Webページを自動的に巡回して情報を収集するロボット(プログラム)のことです。
Googleの検索結果にページが表示されるには、まずクローラーにページを発見してもらう必要があります。クローラーが来なければ、どんなに良いコンテンツを作ってもGoogle検索には表示されません。
「クローラーってそもそも何?」「Googlebotにはどんな種類がある?」「巡回を促すにはどうすればいい?」という疑問をお持ちの方に向けて、クローラーの仕組みから実務で使える対策方法まで詳しく解説します。
\ クロール状態を自動で監視 /
クローラーとは?Webページを自動で巡回するロボット
クローラーは、インターネット上のWebページを自動的に巡回し、ページの内容を収集するプログラムです。「ボット」「スパイダー」「ロボット」と呼ばれることもあります。
Googleの検索エンジンでは、あなたのページが検索結果に表示されるまでに3つのステップを踏みます。
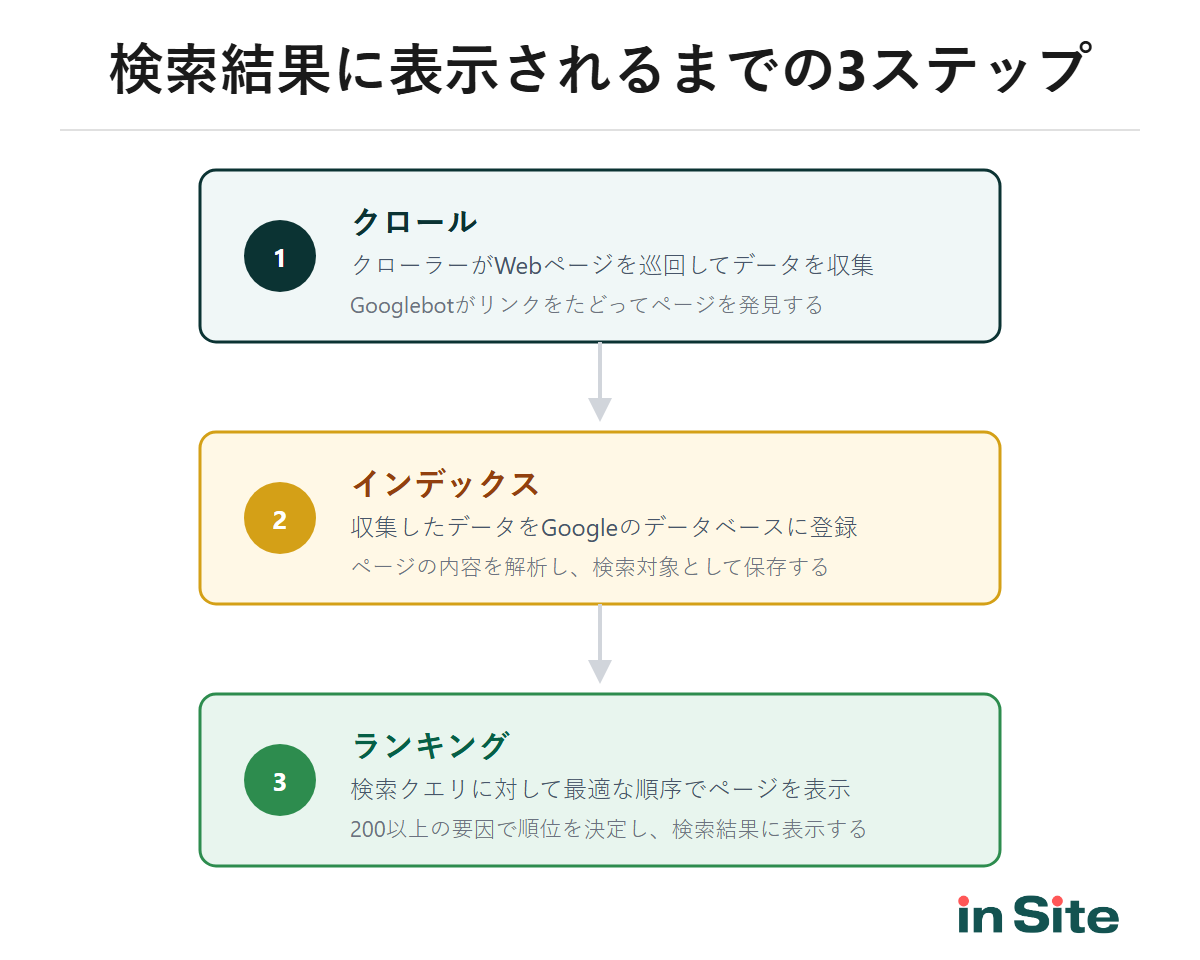
- クロール
クローラーがWebページを巡回してHTMLやリンク情報を収集する - インデックス
収集したデータを解析し、Googleのデータベース(インデックス)に登録する - ランキング
ユーザーの検索クエリに対して最適な順序でページを表示する
クローラーに来てもらうことが、検索結果表示の第一歩です。
関連記事 【2026年最新】SEO対策とは?基礎知識と対策方法をわかりやすく解説 →クロールとインデックスの違い
クロールとインデックスは混同されやすいですが、役割が異なります。
| 項目 | クロール | インデックス |
|---|---|---|
| やること | ページのデータを収集する | 収集データをGoogleのDBに登録する |
| 主体 | Googlebot(クローラー) | Googleのインデクサー |
| 結果 | ページの存在をGoogleが認識する | 検索結果に表示される候補になる |
クロールされたからといって、必ずインデックスされるわけではありません。コンテンツの品質が低い場合や、重複コンテンツと判断された場合、noindexが設定されている場合は、クロールされてもインデックスを見送られることがあります。
「クロールはされたがインデックスされない」という問題については、以下の記事で詳しく解説しています。
関連記事 「クロール済み - インデックス未登録」は放置OK?原因別の判断基準と対処法 →インデックスカバレッジの全ステータスを把握したい方はこちらもあわせてどうぞ。
関連記事 インデックスカバレッジとは?全18ステータスの対処優先度と確認方法 →クローラーとスクレイピングの違い
クローラーとスクレイピングは、どちらもWebページのデータを自動収集する技術ですが、目的と範囲が異なります。
| 項目 | クローラー(検索エンジン用) | スクレイピング |
|---|---|---|
| 目的 | 検索エンジンのインデックス構築 | 特定のデータを抽出・収集 |
| 対象 | Web全体を広く巡回 | 特定のサイト・ページに限定 |
| 動作 | リンクをたどって次々とページを発見 | 決められたページから決められた情報を取得 |
| 例 | Googlebot、Bingbot | 価格比較サイトの商品データ収集、ECサイトの在庫監視 |
| サイトへの影響 | robots.txtを尊重し負荷を制御する | 制御しないものもあり、サーバー負荷になることがある |
SEOの文脈で「クローラー」と言えば、主にGooglebotなどの検索エンジンが運用するクローラーを指します。本記事でもこの意味で解説を進めます。
HTMLのクロール制限(2MB)
意外と知られていませんが、Googlebotがクロールできるのは非圧縮で約2MBまでのHTMLです。2MBを超えた部分は読み取られません。
一般的なWebページであれば2MBを超えることはほとんどありませんが、巨大なテーブルやインラインCSSを大量に含むページでは注意が必要です。
- metaタグ(title、description、robots)は
<head>の上部に配置する - canonicalタグも
<head>の早い位置に書く - 構造化データ(JSON-LD)もHTMLの上部が安全
- 不要なインラインCSS・JavaScriptは外部ファイル化して軽量化する
重要なタグがHTML下部にあると、巨大なページの場合クローラーに読み取られない可能性があります。
Googleのクローラー(Googlebot)の種類
Googleは1種類のクローラーだけでWebを巡回しているわけではありません。用途に応じて複数のクローラーを使い分けています。
| クローラー名 | 用途 | 備考 |
|---|---|---|
| Googlebot(モバイル) | Webページのクロール | メインクローラー。モバイルファーストインデックスの基準 |
| Googlebot(デスクトップ) | Webページのクロール | モバイル版で取得できない情報を補完 |
| Googlebot-Image | 画像のクロール | Google画像検索用 |
| Googlebot-Video | 動画のクロール | 動画検索・動画スニペット用 |
| Googlebot-News | ニュース記事のクロール | Googleニュース掲載用 |
| AdsBot | 広告のランディングページ品質チェック | Google広告出稿時に自動でチェック |
| Storebot-Google | Google Merchant Center | 商品ページの情報取得 |
2024年以降、Googleはモバイル版Googlebotをメインクローラーとして使用しています。これは「モバイルファーストインデックス(MFI)」と呼ばれる方針で、あなたのサイトのモバイル版ページがGoogleの評価基準になるということです。
モバイルSEOの詳しい対策については以下の記事をご覧ください。
関連記事 モバイルSEOとは?スマホ時代に必須の対策と確認方法を実務者向けに解説 →AIクローラーの登場(GPTBot、ClaudeBot等)
2024年から2025年にかけて、AI企業が運用するクローラーが急増しています。これらはGoogleの検索インデックス構築ではなく、AIモデルの学習やAI検索の回答生成を目的としています。
- GPTBot
OpenAI(ChatGPT)のクローラー。AI学習データの収集に使用 - ClaudeBot
Anthropic(Claude)のクローラー。Web検索機能に使用 - PerplexityBot
Perplexity AIのクローラー。AI検索エンジンの回答生成に使用 - CCBot
Common Crawlのクローラー。多くのAI学習データの基盤になっている
AIクローラーはrobots.txtで制御できますが、一部のクローラーがrobots.txtの指示を無視するケースも報告されています。robots.txtに加えて、AI向けの許可・拒否を明示するllms.txtファイルを設置するサイトも増えてきました。
AIクローラーは検索エンジンのクローラーとは別物です。AIクローラーをブロックしても、Google検索のインデックスには影響しません。逆に、Googlebotをブロックしても、AIクローラーには影響しません。それぞれ個別に制御する必要があります。
AIクローラーの具体的なブロック方法を含めたrobots.txtの設定方法は、以下の記事で詳しく解説しています。
関連記事 robots.txtとは?書き方・設置場所・確認方法をわかりやすく解説 →クローラビリティとは?SEOでクローラーが重要な理由
クローラビリティとは、クローラーがサイト内のページをどれだけ効率よく巡回できるかの度合いです。
クローラビリティが低いと、重要なページがクロールされず、検索結果に表示されません。SEO施策の効果を最大化するには、まずクローラーが問題なくサイトを巡回できる状態を作ることが大前提です。

クローラーが好むサイトの特徴
- サーバーの応答速度が速い(TTFB 200ms以下が理想)
- 内部リンクが整理されていて、全ページに3クリック以内で到達できる
- robots.txt、noindex、canonicalが正しく設定されている
- XMLサイトマップが最新の状態でGSCに送信されている
- HTMLが軽量で、重要なメタ情報がソースコード上部にある
- lastmod(最終更新日時)が正確に設定されている
特に内部リンク構造はクローラビリティに大きく影響します。クローラーはリンクをたどってページを発見するため、どこからもリンクされていない「孤立ページ」は発見されにくくなります。
関連記事 【2026年最新】内部リンクとは?SEO効果を高める貼り方と最適化のポイント →クローラーが嫌うサイトの特徴
- サーバーの応答が遅い
Googlebotは応答速度に応じてクロール量を自動調整する。遅いサーバーでは1回の訪問でクロールできるURL数が大幅に減る - 重複コンテンツが大量にある
パラメータURL、wwwあり/なし、スラッシュ有無などで同じ内容のURLが複数存在すると、クローラーが同じ内容を何度もクロールして無駄にバジェットを消費する - サイトの階層が深すぎる
トップページから5クリック以上かかるページは、クローラーが到達しにくい。重要なページは2〜3クリックで到達できる構造にする - JavaScriptに依存した表示
JavaScriptで動的に生成されるコンテンツは、クローラーのレンダリング負荷が高い。通常のHTMLクロールに比べてインデックスまでに時間がかかる場合がある - 孤立ページがある
サイト内のどこからもリンクされていないページは、クローラーが発見できない。XMLサイトマップに含まれていても、内部リンクがないとクロール優先度は低くなる
重複コンテンツの問題については、以下の記事で対策方法を詳しく解説しています。
関連記事 重複コンテンツとは?SEOへの影響と対策方法をわかりやすく解説 →クロールバジェットとの関係
Googlebotはサイトごとにクロールする量の上限(クロールバジェット)を設けています。クローラビリティが低いと、限られたバジェットが不要なページに消費され、本当にクロールしてほしい重要なページに手が回らなくなります。
ただし、数千ページ以下の小〜中規模サイトではクロールバジェットが問題になることはほとんどありません。
関連記事 クロールバジェットとは?確認方法と最適化のポイントをわかりやすく解説 →クローラーの巡回を促進する8つの方法
ここからは、クローラーにサイトを効率よく巡回してもらうための具体的な対策を紹介します。効果が大きい順に並べています。
1. XMLサイトマップを送信する
XMLサイトマップは、クローラーに「このURLをクロールしてほしい」と伝えるためのファイルです。新規サイトや大規模サイトでは特に効果的で、ページの発見速度が大幅に向上します。
サーチコンソールからサイトマップを送信しておくと、新しいページや更新されたページの発見が早まります。lastmod(最終更新日時)を正確に設定しておくと、更新されたページを優先的にクロールしてもらえます。
関連記事 XMLサイトマップとは?SEO効果・作り方・送信方法を実務者向けに解説 →2. 内部リンクを最適化する
クローラーはリンクをたどってページを発見します。重要なページには、サイト内の複数のページからリンクを張っておきましょう。
理想的なサイト構造は、全ページがトップページから3クリック以内で到達できる状態です。「トップ→カテゴリ→記事」のような階層構造を意識し、関連記事間の相互リンクも設置しておくと、クローラーの巡回効率が上がります。
逆に、どこからもリンクされていない「孤立ページ」はクローラーに発見されにくくなります。サイトリニューアルやURL変更の際には、リンク切れが発生していないかの確認も重要です。
関連記事 【2026年最新】内部リンクとは?SEO効果を高める貼り方と最適化のポイント →3. robots.txtを正しく設定する
robots.txtは、クローラーに「このページはクロールしないでください」と伝えるファイルです。
管理画面、テスト環境、検索結果ページ、フィルタ結果ページなどクロール不要なページをブロックすることで、Googlebotが重要なページにクロールを集中させられます。
ただし、robots.txtでブロックしたページにnoindexを設定しても、クローラーがページにアクセスできないためnoindexが読み取れません。noindexを使いたいページはrobots.txtのDisallowから除外する必要があります。
関連記事 robots.txtとは?書き方・設置場所・確認方法をわかりやすく解説 →4. ページの表示速度を改善する
サーバーの応答速度は、Googlebotがクロールする量に直接影響します。
Googlebotはサーバーの応答速度を常にモニタリングしており、応答が速ければ1回の訪問でより多くのページをクロールします。逆に応答が遅いと、サーバーに負荷をかけないよう自動的にクロール量を制限します。
TTFB(Time to First Byte)の改善、画像の最適化、CDNの活用、キャッシュ設定の見直しなどが有効です。
関連記事 ページスピードとは?SEO・CVRへの影響と改善の優先順位を実務者向けに解説 →5. GSCの「URL検査」でインデックス登録をリクエストする
新しいページを公開した直後や、既存ページを大幅に更新した場合は、サーチコンソールのURL検査ツールから「インデックス登録をリクエスト」を実行しましょう。Googlebotに再クロールを促すことができます。
ただし、これは「お願い」であって強制力はありません。リクエストしても必ずしもすぐにクロールされるとは限らないため、サイトマップや内部リンクの整備と併用することが大切です。
関連記事 サーチコンソールでインデックス登録をリクエストする方法【確認・対処法も解説】 →6. 外部リンク(被リンク)を獲得する
外部サイトからのリンクも、クローラーがページを発見するきっかけになります。
Googlebotは外部サイトのリンクをたどって新しいページを発見します。被リンクが多いページほどクローラーの訪問頻度が高くなる傾向があり、リンク元サイトの権威性が高いほどその効果は大きくなります。
関連記事 被リンクとは?SEO効果と自分でできる獲得方法を実務者目線で解説 →7. 定期的にコンテンツを更新する
更新頻度が高いサイトは、Googlebotが「このサイトは新しい情報がありそうだ」と判断し、クロール頻度が上がる傾向にあります。
古い記事のリライトや最新情報の追記、新規記事の追加を定期的に行いましょう。更新の際はXMLサイトマップのlastmodも正確に更新しておくと、クローラーが更新を素早く検知してくれます。
関連記事 コンテンツSEOとは?メリット・手順・成功のコツをインハウス実務者が解説 →8. リダイレクトチェーンを解消する
A → B → C → D のようにリダイレクトが複数回連鎖している「リダイレクトチェーン」は、クローラーの巡回効率を落とします。Googlebotはリダイレクトを最大5回まで追跡しますが、それを超えるとクロールを中断します。
最終URLへの直接リダイレクトに修正し、不要な中間リダイレクトを削除しましょう。
関連記事 リダイレクトチェーンとは?SEOへの影響と確認・解消方法を徹底解説 →クローラーを拒否・制御する方法
特定のページにクローラーを来させたくない場合の制御方法を解説します。方法は2つあり、目的によって使い分けます。
robots.txtでクロールをブロックする
robots.txtにDisallowルールを追加すると、Googlebotのクロール自体をブロックできます。管理画面やテスト環境、フィルタ結果ページなど、そもそもクローラーにアクセスさせたくないページに設定します。
ただし、robots.txtでブロックしたページも、外部からリンクされていると「URLは知っているがコンテンツは不明」という状態でインデックスされることがあります。
関連記事 「robots.txt によりブロックされました」が発生する原因と対処法 →noindexでインデックスだけ除外する
noindexは、クロールは許可しつつインデックスだけを拒否する方法です。「ページの内容はGoogleに認識させたいが、検索結果には表示したくない」という場合に使います。
| 方法 | クロール | インデックス | 主な用途 |
|---|---|---|---|
| robots.txt Disallow | ブロック | されない | 管理画面、テスト環境、フィルタページ |
| noindex | 許可 | 拒否 | サンクスページ、低品質ページ、重複ページ |
クロールされているか確認する方法
クローラー対策を行ったら、効果を確認しましょう。
inSiteで全ページのクロール状態を一括確認
サーチコンソールのURL検査は1ページずつしか確認できません。100ページあるサイトなら100回URLを入力する必要があり、大規模サイトでは現実的ではないでしょう。
サイト管理ツールinSite(インサイト)なら、全ページのクロール日・インデックス状態を自動で取得し、一覧で確認できます。
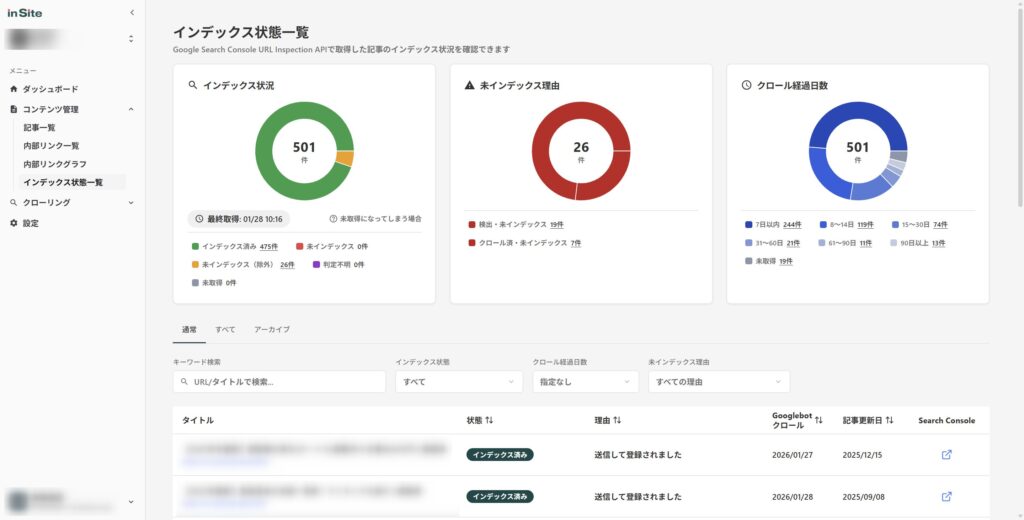
- 最終クロール日の一覧表示
全ページのクロール日を一覧で確認。クロールされていないページや、クロール日が古いまま放置されているページを即座に発見できる - インデックス状態の自動チェック
「インデックス登録済み」「noindexで除外」「クロール済みだがインデックス未登録」など、各ページのステータスを自動で分類・表示 - 変化の検知
前回チェック時からインデックス状態が変わったページを自動で検知。突然インデックスから外れたページに素早く気づける
サーチコンソールの手動確認では「気づいたときには手遅れ」になりがちですが、inSiteなら日常的にモニタリングできるため、問題の早期発見・早期対応が可能です。
GSCの「クロールの統計情報」で確認
サーチコンソールの「設定」→「クロールの統計情報」→「レポートを開く」で、Googlebotのクロール状況をグラフで確認できます。
 サーチコンソール「設定」→「クロールの統計情報」
サーチコンソール「設定」→「クロールの統計情報」
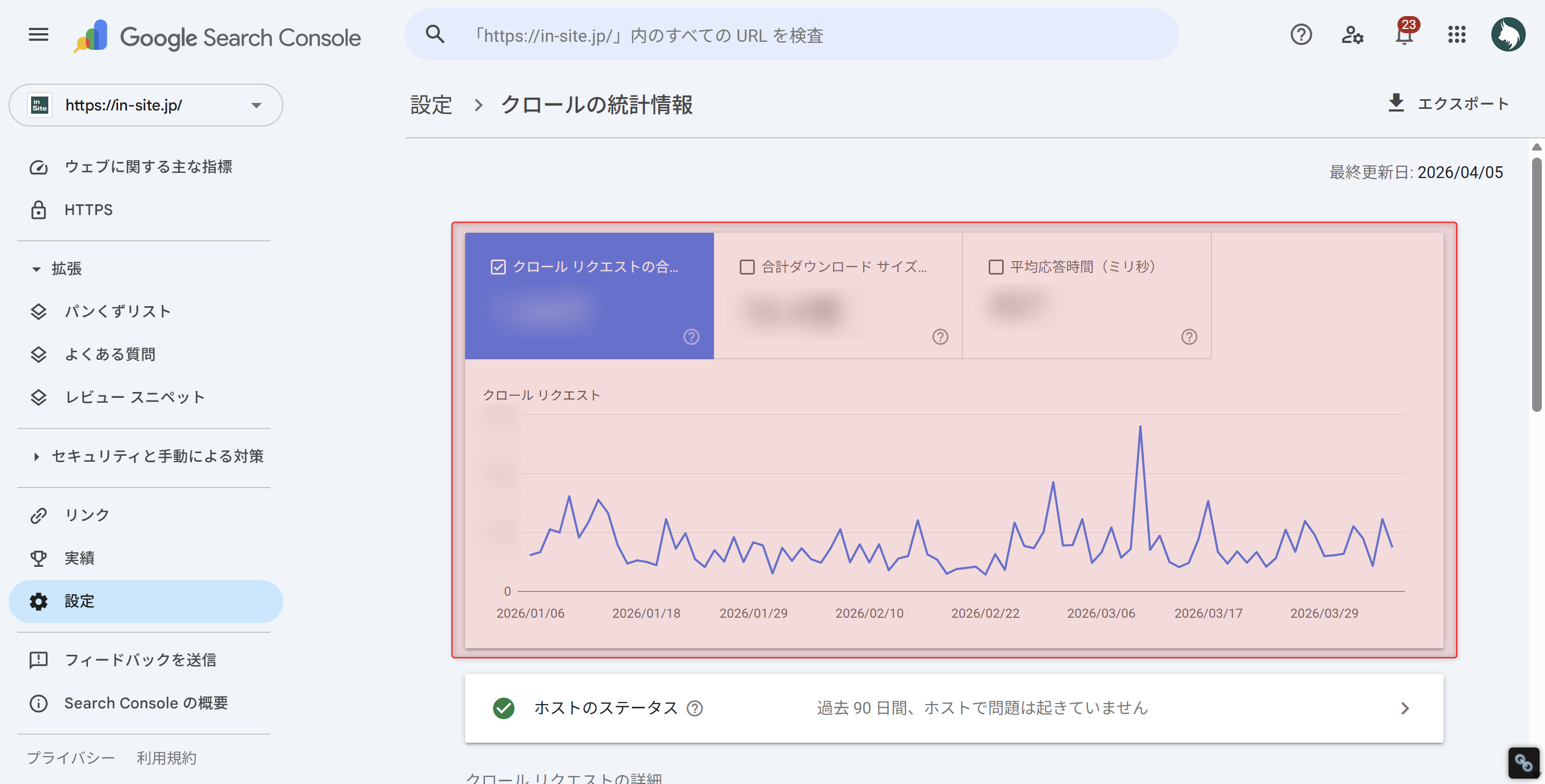 クロールの統計情報レポート(クロールリクエスト数の推移)
クロールの統計情報レポート(クロールリクエスト数の推移)
- クロールリクエストの合計数
1日あたりのクロール数。急激に減少している場合は、robots.txtの誤設定やサーバーエラーの可能性がある - 平均応答時間
サーバーの応答速度。増加傾向ならサーバー改善が必要。200ms以下が理想 - クロールリクエストの内訳
ステータスコード別の割合。404や5xxが多い場合はリンク切れやサーバーエラーの対応が必要
GSCの「URL検査」で個別ページを確認
特定のページがクロールされているかを確認したい場合は、URL検査ツールにURLを入力します。「最終クロール日時」が表示されるので、重要なページのクロール日が古すぎないかチェックしましょう。
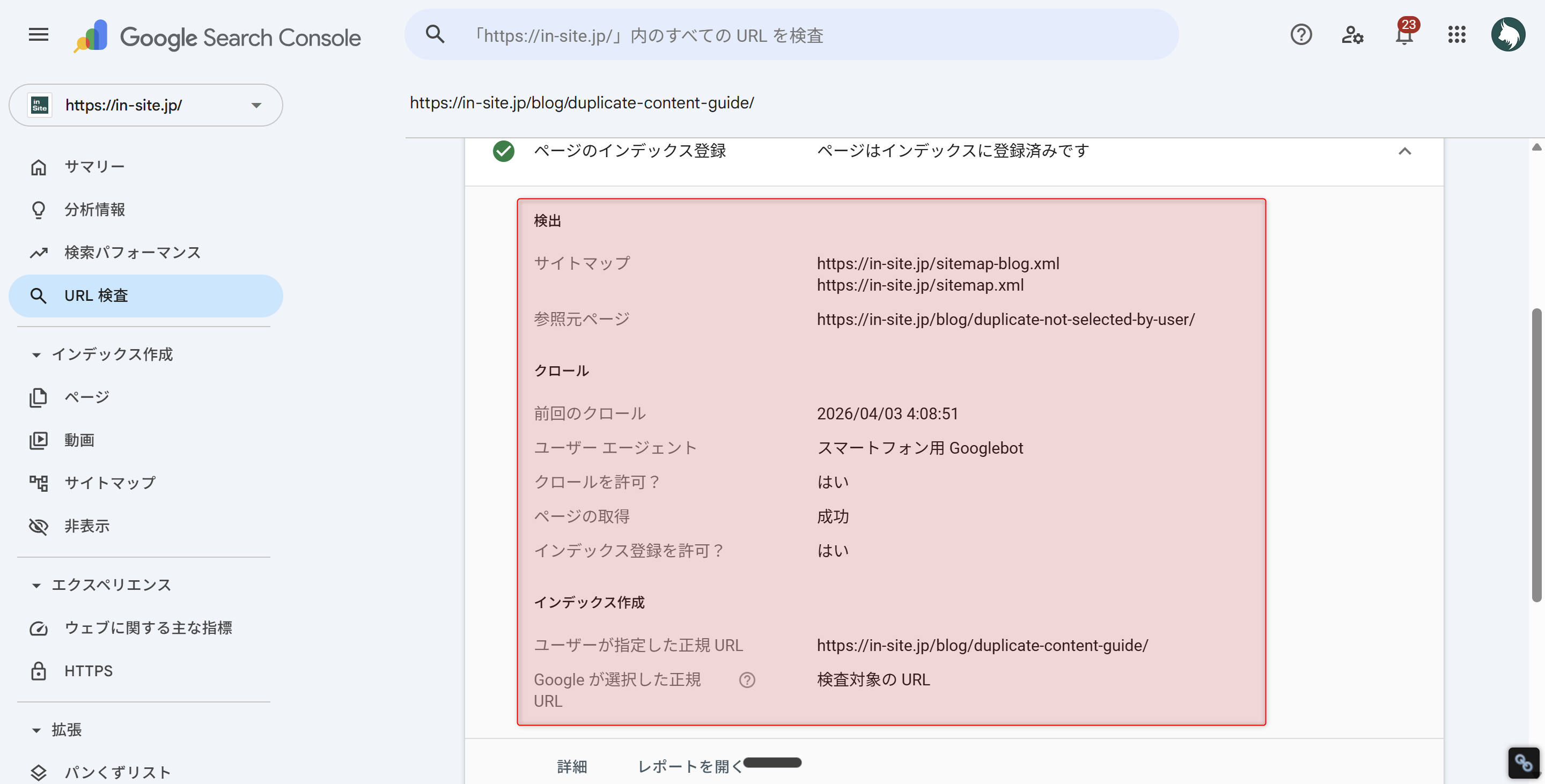 URL検査の結果画面(クロール日時・インデックス状態が確認できる)
URL検査の結果画面(クロール日時・インデックス状態が確認できる)
複数ページを一括で確認したい場合は、以下のツールが便利です。
関連記事 URL Inspection API×GASでインデックス状況を自動一括チェックするスプレッドシート →サイト全体のインデックス数を確認する方法は以下で解説しています。
関連記事 インデックス数の調べ方3選|精度の違いと増えないときの原因・対処法 →Screaming Frog等のツールでクロールシミュレーション
より詳細にクローラビリティを分析したい場合は、Screaming FrogやSitebulbなどの専用ツールが便利です。Googlebotと同じようにサイトを巡回し、リンク切れ、リダイレクトチェーン、孤立ページ、ステータスコードの問題などを網羅的に検出できます。
大規模サイトでは、定期的にクロールシミュレーションを実行して問題を早期発見することをおすすめします。
よくある質問
まとめ
クローラーの仕組みとSEOにおける重要性を解説しました。
- クローラーはWebページを自動で巡回し情報を収集するロボット
- Googlebotにはモバイル版・デスクトップ版など複数の種類がある
- クローラビリティを高めることでインデックスされやすくなる
- robots.txt・サイトマップ・内部リンクの最適化が基本の対策
- GSCの「クロールの統計情報」でクロール状況を確認できる
クローラーに来てもらえなければ、そのページは検索結果に表示されません。まずはサーチコンソールの「クロールの統計情報」で現状を確認し、クロール数や応答時間に異常がないかチェックすることから始めてみてください。
\ クロール状態を自動で監視 /