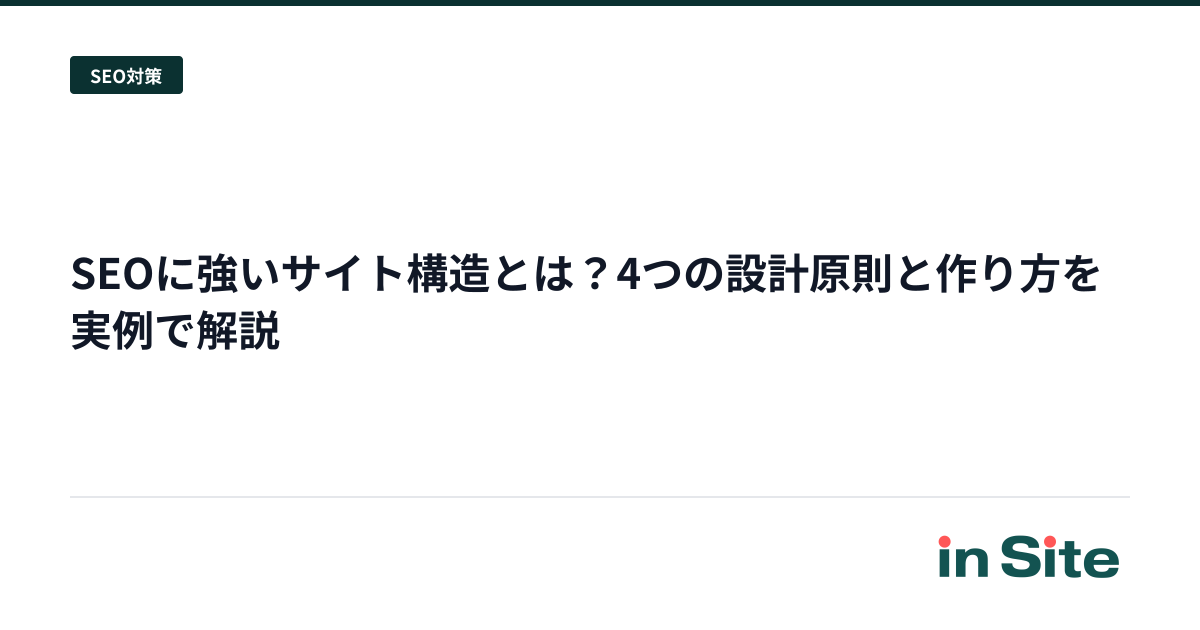
インデックス数とは、検索エンジンがデータベースに登録しているWebページの数
インデックス数とは、検索エンジンが検索結果に出す候補としてデータベースに登録しているWebページの数のことです。本記事ではGoogleを前提に解説しますが、Bing・Yahoo!などの他の検索エンジンにも、それぞれ独自のインデックスがあります。
Googleの場合、サイト内に存在するページ数とは一致せず、Googleが「検索結果に出す価値がある」と判断したページだけがカウントされます。
Googleは、URL発見 → クロール → レンダリング → canonical選択・重複整理 → インデックス判断、という処理を経て、最終的に検索結果に出す候補として保持するかを決めます。クロールしたページがすべてインデックスされるわけではない点が、最も誤解されやすい部分です。
そのため、サイト内のURL数とインデックス数が一致しないこと自体は珍しくありません。noindex・canonical・重複・低品質・robots.txtブロックなどの理由で、Google側が「検索結果に出さない」と判断したURLは、そもそもインデックス数に含まれません。インデックスの仕組み全体を整理したい場合はインデックスカバレッジの全ステータスで詳しく解説しています。
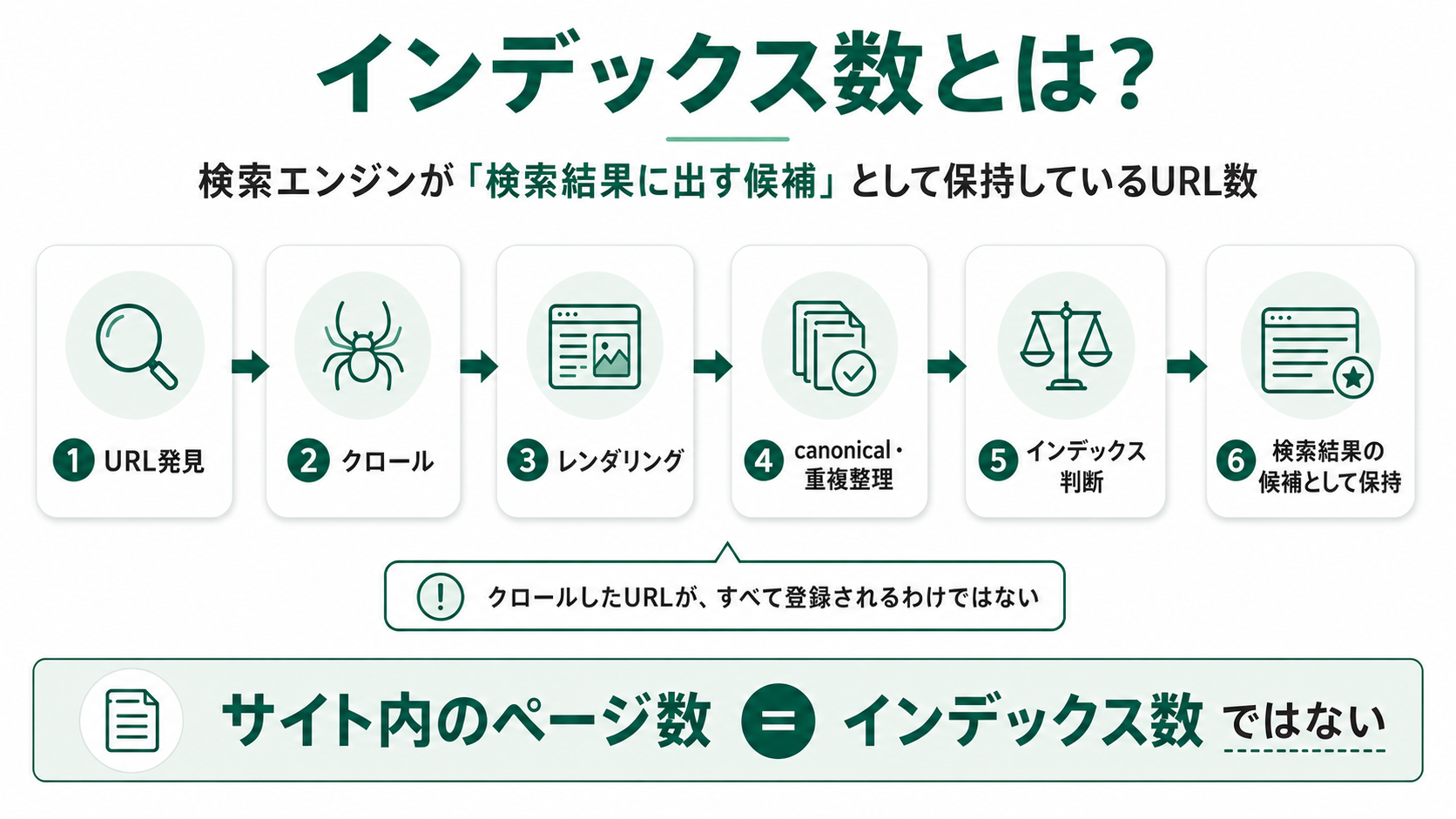
インデックス数を確認する4つの目的
インデックス数を確認する目的は、主に「重要ページの登録漏れ」「異常な増減の検知」「未登録理由の把握」「競合の規模感把握」の4つです。それぞれ見るポイントが違うため、目的を意識して確認するとSEO施策の判断に直結します。
重要ページがインデックスされているか確認する
検索流入を狙う重要URL(記事・サービスページ・カテゴリページなど)が、Googleに「検索結果に出す候補」として保持されているかを確認しましょう。
総数よりも、意図したページが登録されているかが大事です。重要ページが未登録のまま放置されていれば、検索流入の機会を取りこぼしている可能性があります。サイト規模が大きくなるほど、ページ単位のチェックが効いてきます。
インデックス数の急増・急減から異常を検知する
インデックス数の急変は、サイト側で何かが起きているサインです。
急減は、noindexの誤設定・robots.txtの変更ミス・canonicalの変更・リダイレクトや404の増加・サイトマップの変更などの兆候として現れます。急増は、低品質URLや絞り込みURL・パラメータURL・サイト内検索結果ページなどが大量に登録されている可能性があります。
数値の変化そのものを評価するのではなく、「原因調査の入口」として扱うのが実務的な使い方です。
インデックス未登録理由から改善箇所を把握する
Search Consoleでは、未登録URLの理由(noindexタグ・重複・クロール済み未登録・検出未登録など)を細かく確認できます。それぞれの読み方と対処はインデックスカバレッジの全ステータスで詳しく解説しています。
未登録URLがあること自体が問題なのではなく、「意図した未登録」か「意図しない未登録」かを切り分けることが改善の出発点になります。意図したnoindex・canonicalによる未登録は健全ですが、重要ページが意図せず未登録になっている場合は対応が必要です。
競合サイトやディレクトリの規模感を把握する
site:コマンドやSEOツールは、競合サイトのインデックス規模を概算で把握するのに使えます。
ただし正確なインデックス数を返す機能ではないため、「数百規模か、数万規模か」程度の把握にとどめましょう。競合の絶対値を細かく追うよりも、自社サイトとの規模差や成長ペースの違いを見るほうが実用的です。
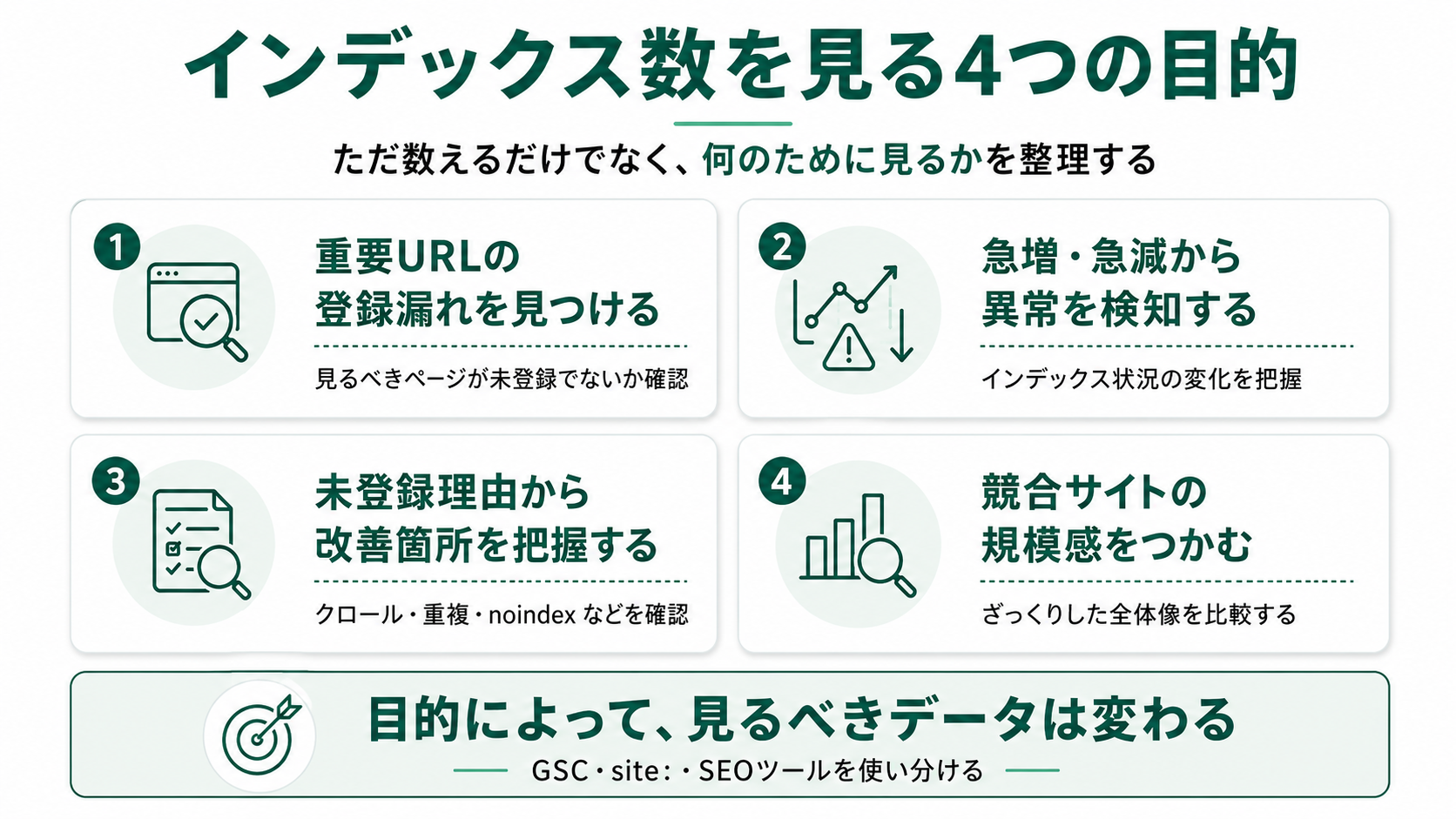
インデックス数を確認する方法は大きく3つある
インデックス数の確認方法は、Google Search Console・site:コマンド・SEOツールの3つに分かれ、それぞれ用途と精度が違います。用途を取り違えるとデータの読み違いにつながるため、最初に役割を整理しておきましょう。
3つの確認方法の用途と精度
- Google Search Console(自サイトの正確な診断用)
- site:コマンド(競合・ディレクトリのざっくり規模確認用)
- SEOツール(推移・競合比較・補助分析用)
Google Search Consoleで自サイトのインデックス状況を確認する
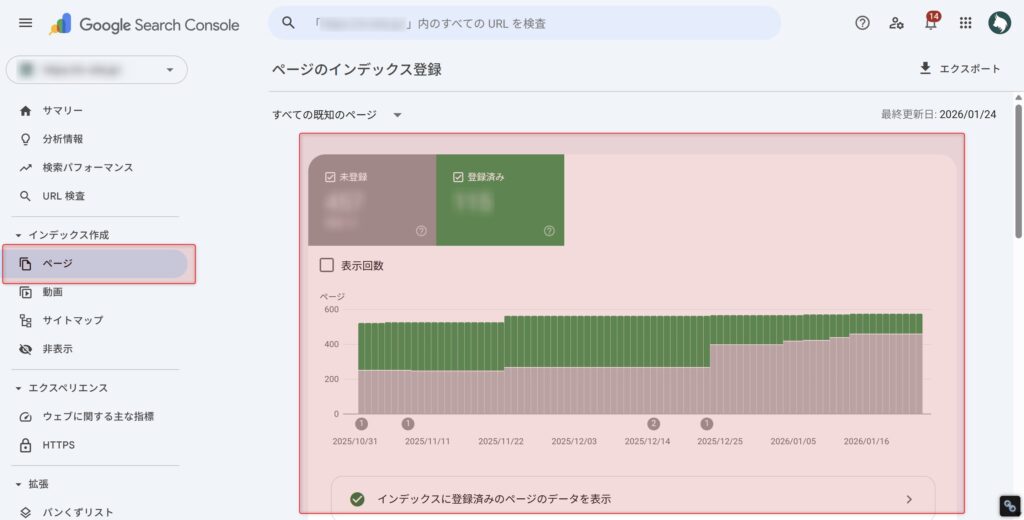
自サイトのインデックス状況を見るときは、Search Consoleを使いましょう。「ページのインデックス登録」レポートで、登録済み数と未登録の理由を併せて確認できます。
確認手順は次のとおりです。
STEP 2
左メニューの「インデックス作成」 → 「ページ」を開く
STEP 3
「登録済み」のページ数と、未登録の内訳を確認する
STEP 4
重要URLは「URL検査」で個別にインデックス状況を確認する
登録済みの数値だけを見るのではなく、未登録の理由(noindexタグ・重複・クロール済み未登録など)も併せて確認するのがポイントです。重要ページが未登録になっていないかを優先して点検しましょう。
詳しい操作手順はページインデックス登録レポート(Google公式ヘルプ)を、各ステータスの読み方と対処法はインデックスカバレッジの全ステータスを参照してください。
site:コマンドでGoogle検索上の概算を確認する
site:コマンドは、Google検索上で概算のインデックス数を確認するための補助的な方法です。正確な件数を返す機能ではないため、診断用途には向きません。
基本的な使い方は次のとおりです。
比較表
| 用途 | クエリ例 |
|---|
| ドメイン全体の概算 | site:example.com |
|---|
| 特定ディレクトリのみ | site:example.com/blog/ |
|---|
| キーワードと組み合わせ | site:example.com 検索キーワード |
|---|
なお、Google検索結果の件数表示は2024年5月以降のUI変更でデフォルト非表示になっています。件数を確認したい場合は、検索結果ページ上部の「ツール」をクリックしてください。
site:コマンドを使うときの注意
- site:コマンドは、Googleにインデックスされている全URLを正確に返す機能ではない
- Search Consoleの数値とは一致しない前提で使う
- 「数百ページ規模か、数万ページ規模か」のような桁数の把握に使う
- 細かい増減比較には使わない
site:コマンドが活きるのは、Search Consoleで見られない競合サイトやディレクトリ単位の規模感を把握したいケースです。あくまで概算・傾向確認用と割り切って使い分けましょう。
SEOツールで競合サイトや推移を補助的に確認する
AhrefsやSemrushなどのSEOツールは、競合比較や推移分析の補助として活用しましょう。ツールが取得しているインデックス数も、Googleの実数そのものではない点を理解しておきましょう。
比較表
| 用途 | 主に使うツール例 |
|---|
| 無料で簡易チェック | SEOチェキなど |
|---|
| 競合サイトの推移分析・URL内訳確認 | Ahrefs / Semrush など |
|---|
| サイト内の全URLクロール | Screaming Frog など |
|---|
| 自サイトのインデックス状況・未登録理由を毎日自動追跡 | inSite など |
|---|
SEOツールの数値はGoogleの実インデックス数とは差異が出ることが一般的です。自サイトの正確な診断はSearch Console、競合比較・推移分析はSEOツール、規模感の把握はsite:コマンドと用途を分けて使いましょう。Search Consoleで確認できるのは現時点のスナップショットなので、自サイトのインデックス状況や未登録理由の推移を継続的に追いたい場合は、毎日自動でデータを取得・記録する専用ツールを併用すると効率的です。
Google Search Consoleでは「登録済み数」だけでなく「未登録の理由」を見る
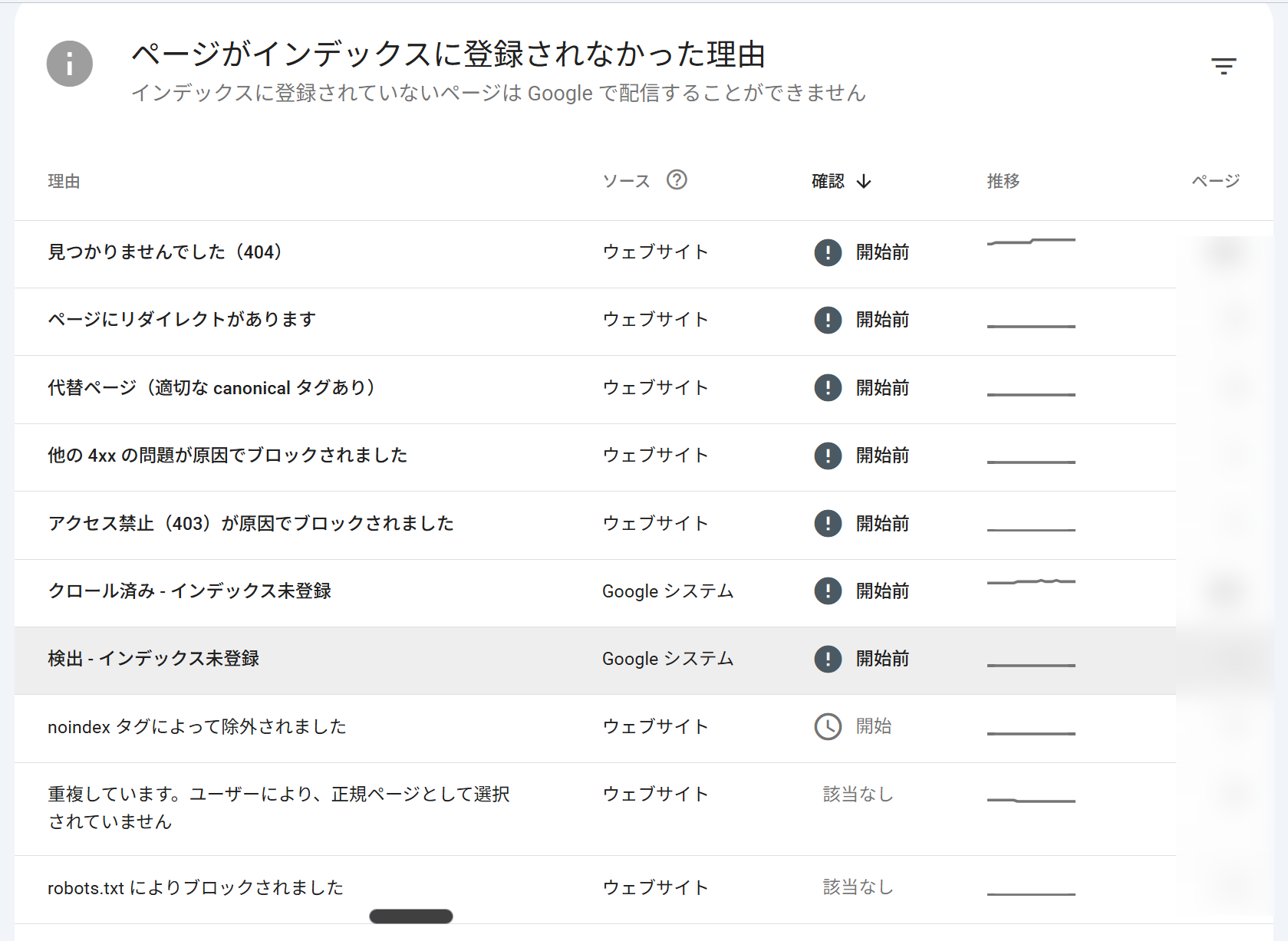
Search Consoleの「ページ」レポートは、登録済みのURL数だけでなく、未登録URLの理由を確認するのが本来の使い方です。未登録の理由ごとに見るべき場所と対処が変わるため、主要なステータスの読み方を押さえておきましょう。

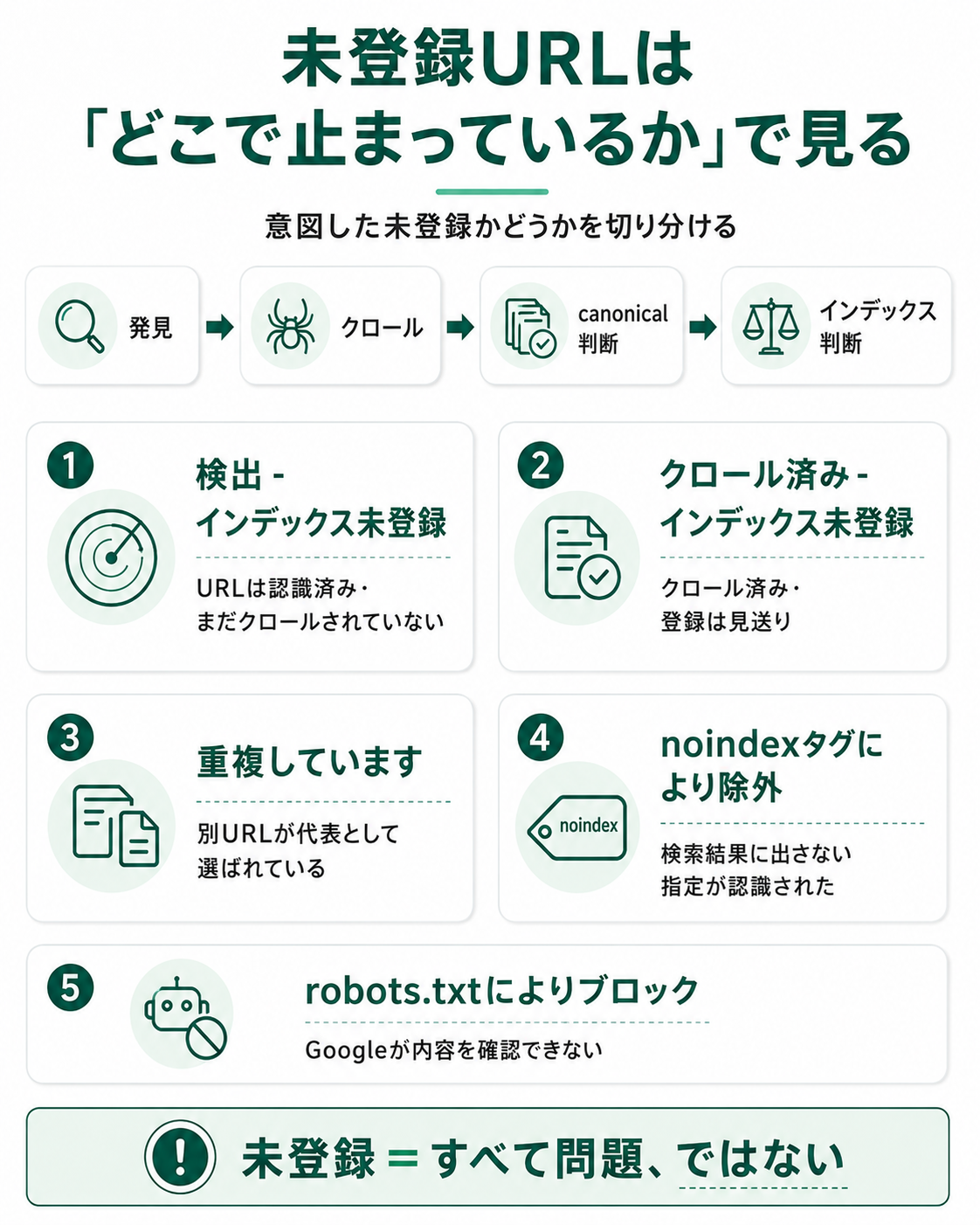
「検出 - インデックス未登録」は、URL発見後にクロールされていない状態
「検出 - インデックス未登録」は、GoogleがそのURLを認識しているものの、まだクロールしていない状態です。
内部リンクが弱い・サイト全体のURL数が多すぎる・クロール優先度が低い・サーバー応答が不安定などの可能性があります。重要URLにこのステータスが付いている場合は、内部リンク・XMLサイトマップ・サーバー応答など、クロールに到達するまでの導線を見直してください。
具体的な切り分けは「検出 - インデックス未登録」を解消する5つの対策で詳しく解説しています。
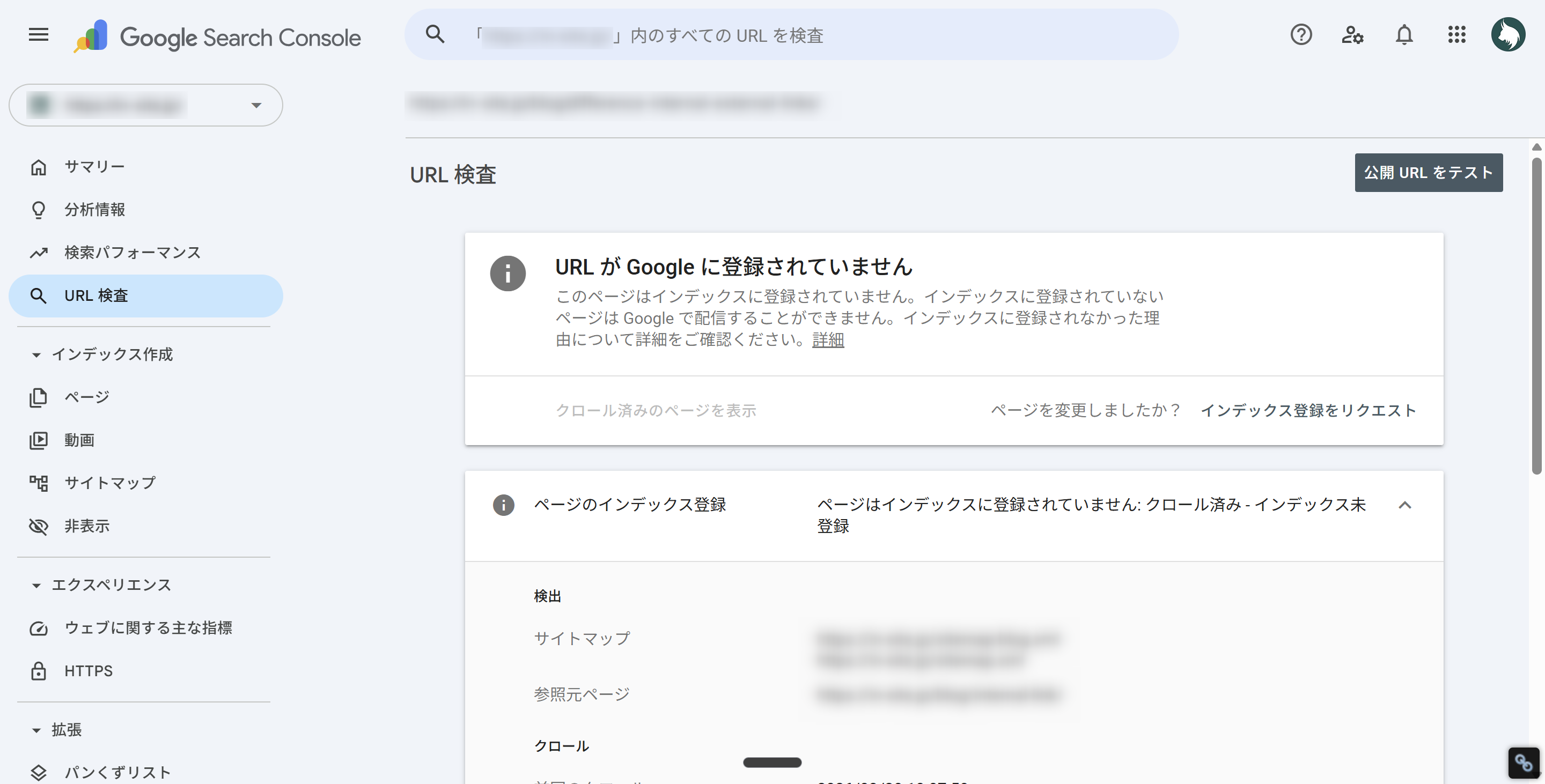
「クロール済み - インデックス未登録」は、クロール後に登録されていない状態
「クロール済み - インデックス未登録」は、Googleがページをクロールしたものの、インデックスには登録していない状態です。
ここで見るべきはクロール量ではなく、ページ品質・既存ページとの重複・別URLをcanonicalにしていないか・検索意図とのズレ・内部リンクからの到達経路です。重要ページにこのステータスが付いている場合は、本文の独自性・検索者にとっての判断材料・内部リンク経路を見直しましょう。
原因の切り分け方は「クロール済み - インデックス未登録」の原因と対処で詳しく解説しています。類似ステータスとして、サーバーは200を返しているのに中身が薄くて404扱いされるソフト404エラーや、インデックス登録されたものの本文が認識されていないコンテンツのない状態でインデックス登録もあります。どれもページの中身が原因で起きるので、対処の方向は同じです。
「重複しています」は、Googleが別URLを代表として選んでいる状態
「重複しています」系のステータス(重複しているがcanonicalタグなし、重複しています:ユーザーにより、正規ページとして選択されていません など)は、Googleがそのページを別URLの重複と判断している状態です。
ユーザー指定canonicalとGoogle選択canonicalが一致しているかを確認しましょう。canonicalタグ・内部リンク・XMLサイトマップ・パンくずリスト・構造化データのURLが揃っていれば、Googleの判断は安定しやすくなります。canonicalの仕組みはcanonicalによる正規URLの指定で解説しています。
個別ステータスへの対処は、ユーザーがcanonicalを指定していないケースは「重複しています。ユーザーにより、正規ページとして選択されていません」の対処、ユーザー指定とGoogle選択がズレているケースは「Googleにより、ユーザーがマークしたページとは異なるページが正規ページとして選択されました」の対処を参照してください。
「noindexタグにより除外」は、検索結果に出さない指定が認識された状態
「noindexタグにより除外」は、サイト側がnoindexで「検索結果に出さない」と指定し、Googleがそれを認識している状態です。
noindexが意図通りに設定されている場合は問題ありません。重要ページに誤ってnoindexが入っていないかを確認しましょう。meta robotsだけでなく、HTTPレスポンスヘッダーのX-Robots-Tagにも目を通しておきましょう。noindexそのものの書き方・設定方法はnoindexとは?書き方・設定方法・確認方法、ステータス別の対処はnoindexタグによる除外の対処法を参照してください。
「robots.txtによりブロック」は、Googleがページ内容を確認できない状態
「robots.txtによりブロック」は、Googleがクロール自体できないため、ページ内容・noindex・canonicalを確認できない状態です。
robots.txtはクロール制御の仕組みで、インデックス制御ではありません。noindexで除外したいページをrobots.txtでブロックしてしまうと、Googleがnoindexを読めず、検索結果に残り続けることがあります。重要ページが誤ってブロックされていないか、Disallowルールも併せて確認しましょう。詳しい対処はrobots.txtによるブロックの対処法で解説しています。なお、robots.txtでブロックしているのに外部リンク経由でURLだけインデックスされてしまうケースは「robots.txtによりブロックされましたが、インデックスに登録しました」の対処を参照してください。
site:コマンドは正確な件数ではなく、ざっくりした規模感を見るために使う
site:コマンドは、Search Consoleで見られない領域(競合サイトやディレクトリ単位)の規模感をざっくり把握するための補助手段です。正確な件数を返す機能ではないので、用途を絞って使いましょう。

自サイト全体の概算を確認する
site:自社ドメイン で、サイト全体のおおよそのインデックス規模を確認できます。Search Consoleの数値とずれることは普通なので、概算として捉えましょう。
公開ページ数に対してsite:コマンドの件数が極端に少ない場合は、Search Consoleで未登録の理由を併せて確認しましょう。
特定ディレクトリ配下の概算を確認する
site:example.com/blog/ のように、ディレクトリを絞って規模感を見ることもできます。
ブログ・カテゴリ・求人・商品一覧などのディレクトリ単位で、極端に少ない・極端に多い領域がないかを確認するのに使えます。膨らみすぎている領域は、不要URLの整理候補として検討しましょう。
競合サイトのインデックス規模をざっくり見る
site:コマンドは、自社では確認できない競合サイトの規模をざっくり把握する用途に向きます。
ただし正確な比較には向かないため、「自社が数千ページ、競合が数万ページ」のような桁レベルの差を読み取る程度にとどめましょう。競合分析では、ページ数だけでなく、流入キーワード・コンテンツ構成・内部リンク設計なども併せて見る必要があります。
Search Consoleの数値とは一致しない前提で使う
site:コマンドの件数とSearch Consoleの登録済み数は、ほぼ一致しません。Googleが検索結果上で表示する数は推定値であり、診断用には設計されていないためです。
自サイトの状態確認はSearch Console、競合や規模感はsite:コマンドと、最初から用途を分けて使うのが結局いちばんシンプルです。
インデックス数が多ければSEOに強いわけではない
インデックス数が多いことと、SEOで成果が出ていることは別の話です。総数を増やすことを目標にすると、かえってサイト全体の品質を落としやすいので、「数」より「中身」で判断しましょう。

重要ページが登録されていないと、検索流入の機会を逃す
総数がいくら多くても、検索流入を狙う重要ページが登録されていなければ、本来取れていたはずの流入を取り逃がしている状態です。
インデックス数を見るときは、総数の大小ではなく「登録されるべきURLが登録されているか」を最初の判断軸にしましょう。重要ページが未登録のときは、内部リンク・XMLサイトマップ・noindex・canonical・コンテンツ品質の順に原因を切り分けてください。
低品質ページや重複ページが大量にあると、サイト全体の評価を下げる
空ページ・内容の薄いページ・重複ページ・絞り込みやパラメータで自動生成されたURLが大量にインデックスされていると、サイト全体の品質評価を下げる原因になります。
Googleに見せたいURLがぼやけ、クロールバジェットが重要URL以外に分散しやすくなります。本来検索結果に出したいページを埋もれさせないためにも、見せる必要のないURLは積極的に整理しましょう。
検索結果に出す必要がないページは、noindexやcanonicalで除外する
サイト内検索結果ページ・絞り込み・並び替え・サンクスページ・印刷用ページ・テスト用ページなど、検索結果に出す必要がないページはnoindexやcanonicalで意図的に除外しましょう。
「インデックス対象にするURL」を決めることと同じくらい、「インデックス対象にしないURL」を決めることも大事です。除外設計まで含めて、はじめて健全なインデックス管理と言えます。
見るべきなのは総数ではなく、登録されるべきURLが登録されているか
ここまでの話をまとめると、インデックス数の見方は次の4点に整理できます。
健全なインデックス管理の見方
- 検索流入を狙う重要URLが登録されているか
- 意図せず未登録になっているURLがないか
- 低品質・重複・自動生成のURLが大量に登録されていないか
- noindex・canonical・robots.txtで意図的に除外している領域が設計通りか
総数の増減ではなく、URL設計の意図と実態が一致しているかを基準に判断するのが、健全なインデックス管理の出発点になります。
インデックス数が増えないときは、Googleの処理工程ごとに原因を切り分ける
インデックス数が増えない原因は、Googleの「URL発見 → クロール → 除外設定の確認 → canonical判定 → 内容評価」という処理工程のどこかに引っかかっているケースが多くあります。1つの原因に決めつけず、工程ごとに切り分けて確認しましょう。

GoogleがURLを発見できているか確認する
そもそもURLが発見されていなければ、クロールもインデックスも始まりません。
内部リンクから到達できるか・XMLサイトマップに含まれているか・どこからもリンクされていない孤立ページになっていないか・JavaScript依存のリンクだけで構成されていないかを確認しましょう。新規ページを公開したら、関連ページの本文中・カテゴリ・パンくずなど複数経路でリンクすると発見されやすくなります。
Googlebotがクロールできる状態か確認する
URLが発見されていてもクロールできなければ、その先には進みません。
HTTP 200を返しているか・robots.txtでブロックしていないか・5xxサーバーエラーが頻発していないか・リダイレクトチェーンになっていないかをチェックしましょう。サーバー応答が安定していないとクロール頻度が下がるため、クロール容量の観点でもサーバー安定化は効きます。
noindexやrobots.txtで除外していないか確認する
クロールはできているのに、サイト側の除外設定でインデックスから外れているケースもあります。
noindexは検索結果から除外する指定、robots.txtはクロールさせない指定です。役割を混同しないこと、重要ページに誤って設定されていないことを確認しましょう。役割の違いはnoindexはインデックス制御・robots.txtによるクロール制御で詳しく解説しています。
canonicalが別URLを指していないか確認する
canonicalで別URLを正規として指定していると、そのページはインデックスされません。
canonicalタグ・Google選択canonical・内部リンク・XMLサイトマップ・パンくず・構造化データ内のURLが、すべて同じ正規URLを指しているかを確認しましょう。URLシグナルがバラついているとGoogleの判断が安定せず、意図しないURLが代表として選ばれやすくなります。
ページ内容が検索結果に出す価値を持っているか確認する
クロールも設定もクリアしているのに登録されない場合は、内容の評価段階で止まっている可能性があります。
検索者の疑問にしっかり答えられているか・既存ページとの差別化があるか・独自情報や具体例・図解・FAQが備わっているかを点検しましょう。「クロール済み - インデックス未登録」が増えているサイトは、まずここを見直しましょう。
インデックス数を健全に保つには、Googleに見せたいURLを整理する
インデックス数を健全に保つには、新しいURLをひたすら追加するのではなく、Googleに見せたいURLを意図して整理することが基本になります。
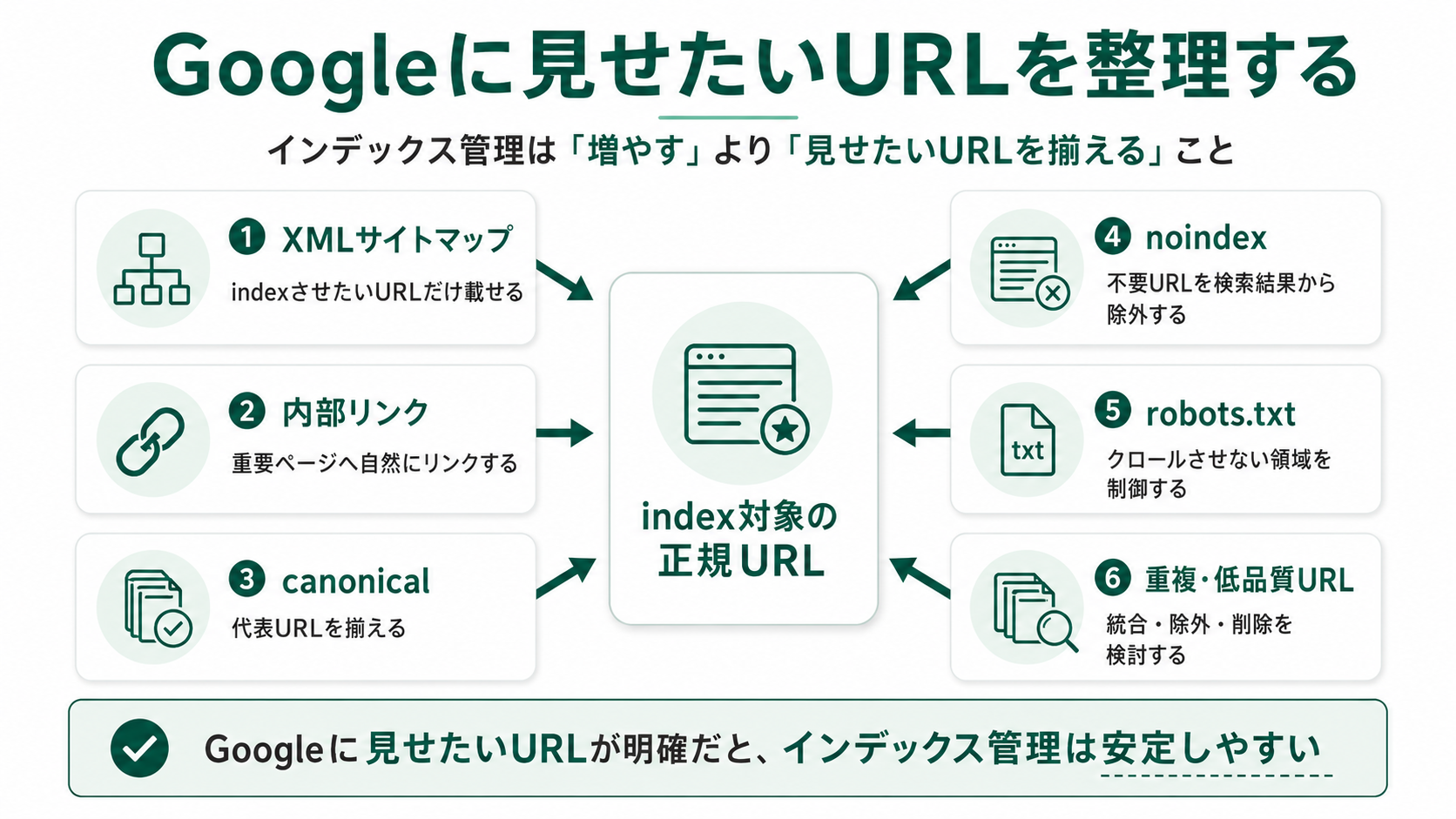
XMLサイトマップにはindexさせたい正規URLを載せる
XMLサイトマップは、サイト内に存在する全URLの一覧ではなく、Googleに見てほしい正規URLを整理して伝えるためのファイルです。
HTTP 200を返す・index対象である・canonicalが自己参照しているURLを中心に載せ、noindex・3xx・4xx・別URLをcanonicalにしているURLは含めないようにしましょう。詳しい運用はXMLサイトマップに載せるURLで詳しく解説しています。
内部リンクで重要ページへ自然に到達できるようにする
重要ページは、本文中・カテゴリ・関連リンクなどから自然に到達できる状態にしておきましょう。
サイドバーやフッターのリンクだけに頼ると、関連性の弱いリンクが多くなりやすく、Googleにとっての重要度シグナルも弱くなります。アンカーテキストは「こちら」のような汎用表現ではなく、リンク先の内容が分かる表現にしましょう。設計の考え方は内部リンクの効果と最適な貼り方を参照してください。
重複・低品質・空ページは統合や除外を検討する
似た内容の記事・薄い記事・空ページが残ったまま増えていくと、サイト全体のインデックス品質を下げる原因になります。
統合・リライト・noindex・canonical・削除のどれで対応するかは、ページごとの目的と検索意図で判断しましょう。「とにかく残す」のではなく、Googleに見せたいURLだけを意図的に残す視点で判断するのが基本です。
robots.txtとnoindexの役割を混同しない
実装上のミスで多いのが、robots.txtとnoindexの混同です。
robots.txtでブロックしたページは、Googleがクロールできなくなるため、noindexタグが書いてあっても認識されません。「検索結果に出したくないからrobots.txtでブロック」は、外部からリンクされていればURLだけ検索結果に表示される場合があり、確実な除外手段にはなりません。検索結果から確実に外したい場合はnoindex(=クロール可能な状態でnoindexを書く)を使いましょう。
canonical・内部リンク・サイトマップのURLを揃える
canonicalタグだけを設定しても、内部リンクやサイトマップが別URLを指していると、Googleの判断は安定しません。
canonicalタグ・内部リンク・XMLサイトマップ・パンくず・構造化データ・href属性の表記(http/https・末尾スラッシュ・wwwの有無)を、サイト全体で同じ正規URLに揃えましょう。シグナルが一貫しているほど、Googleが正規URLを選びやすくなり、意図しない重複扱いも減らせます。
インデックス数に関するよくある質問
インデックス数が多いほどSEOに強いですか?
いいえ、多いほど強いわけではありません。重要なのは、検索結果に出す価値があるページが正しくインデックスされているかです。低品質ページ・重複ページ・空ページ・絞り込みやパラメータURLまで大量にインデックスされている場合は、URL管理やコンテンツ品質の見直しが必要です。総数ではなく、登録されるべきURLが登録されているかを判断軸にしてください。
Search Consoleのインデックス数とsite:コマンドの件数が違うのはなぜですか?
Search Consoleは自サイトのインデックス状況を確認するための公式データで、登録済み数も推定値ではあるものの最も信頼できる数値です。一方、site:コマンドはGoogle検索上で確認できる概算で、正確なインデックス数を返す機能ではありません。自サイトの状態確認にはSearch Consoleを、競合サイトやディレクトリの規模感を見るときはsite:コマンドを、というように用途を分けて使い分けましょう。
インデックス未登録が多いのは問題ですか?
未登録URLが多いだけで問題とは限りません。noindexページ・削除済みページ・重複ページ・検索結果に出す必要がないURLが未登録になっているのは健全な状態です。問題なのは、重要な記事やサービスページが意図せず未登録になっているケースです。Search Consoleの「ページ」レポートで未登録の理由を確認し、内部リンク・XMLサイトマップ・noindex・robots.txt・canonical・コンテンツ品質を順に見直しましょう。
「検出 - インデックス未登録」と「クロール済み - インデックス未登録」は何が違いますか?
「検出 - インデックス未登録」は、GoogleがURLを認識しているもののまだクロールしていない状態です。内部リンクが弱い・サイト全体のURLが多すぎる・クロール優先度が低いなどの可能性があります。「クロール済み - インデックス未登録」は、Googleがページをクロールしたうえでインデックスに登録していない状態で、品質・重複・canonical・検索意図とのズレを確認する必要があります。同じ未登録でも、見るべき場所が大きく違います。
robots.txtでブロックすればインデックスされませんか?
robots.txtはクロールを制御する仕組みで、インデックスを直接制御するものではありません。robots.txtでブロックしても、外部からリンクされていればURLだけ検索結果に表示される場合があります。検索結果に出したくないページには、基本的にnoindexを使いましょう。ただしnoindexを認識してもらうには、Googlebotがそのページをクロールできる必要があるため、robots.txtでブロックしたままnoindexを書いてもGoogleには伝わりません。
noindexページはXMLサイトマップに入れてもよいですか?
基本的には入れない方がよいです。XMLサイトマップはGoogleに「見てほしいURL」を伝えるファイルで、noindexは「検索結果には出さないでほしい」という指定です。両方を同じURLに対して送ると、矛盾したシグナルになります。サイトマップにはindex対象の正規URLだけを載せ、noindexページは除外する運用が基本です。
インデックス数が急に減ったときは何を確認すべきですか?
まずSearch Consoleの「ページ」レポートで、どの理由の未登録URLが増えているかを確認しましょう。特に注目したいのは、noindexの誤設定・robots.txtのブロック追加・canonicalの変更・リダイレクトや404の急増・XMLサイトマップの変更・サイトリニューアルやCMS更新によるURL構造の変化です。これらが直近の作業と紐付いていないかを確認すると、原因の切り分けが早くなります。
このほかの未登録ステータスの読み方はインデックスカバレッジの全ステータスで、SEO施策全体のチェックはSEOチェックリストで確認できます。クロールの仕組みそのものはクローラーの仕組み・クロールバジェットの考え方もあわせて参照してください。
まとめ
インデックス数は、検索エンジンが検索結果の候補として保持しているページの数です。見るべきは総数の大小ではなく、登録されるべきURLが正しく登録されているかどうか。
未登録の理由をSearch Consoleで継続的にチェックするだけで、サイトの状態はぐっと把握しやすくなります。
この記事のポイント
- インデックス数とは、検索エンジンが検索結果の候補として保持しているURL数のこと
- 確認方法はSearch Console・site:コマンド・SEOツールの3つで、それぞれ用途が違う
- 自サイトの状態はSearch Console、競合や規模感はsite:コマンドと使い分ける
- 登録済み数だけでなく、未登録URLの理由を読むのが本来の使い方
- 「検出 - インデックス未登録」はクロール待ち、「クロール済み - インデックス未登録」は品質・重複が原因
- インデックス数は多ければよいわけではなく、登録されるべきURLが登録されているかを見る
- robots.txt・noindex・canonical・XMLサイトマップは役割が違うので混同しない
- 急変は異常のサインとして扱い、Googleの処理工程ごとに原因を切り分ける
ただ、Search Consoleで未登録の理由まではわかっても、内部リンク不足・canonical不一致・noindexの誤設定・XMLサイトマップの問題のどれが原因かを切り分けるには、複数の情報を突き合わせる必要があります。これを毎日手作業で続けるのは、正直しんどいですよね。
inSiteなら、未インデックスの理由・canonical不一致・内部リンク不足など、未登録URLの原因となる問題を毎日自動で検出。重要度順に並ぶので、何から直すべきかが一目でわかります。
検出ルールは標準で10種類、解決した問題は自動で消えるので、いま対処すべきタスクだけが残る運用に変わります。下のリンクから無料で試せるので、ぜひ実際の画面を見てみてください。